이코에코(Eco²) Message Queue #7: Celery Chain + Celery Events (2)
이전 글: Celery Chain + Celery Events (1)
관련 트러블슈팅: Celery + RabbitMQ 트러블슈팅 가이드
개요
본 문서는 4단계 Scan Pipeline + Fire&Forget RDB 저장으로 고도화된 Celery Chain 아키텍처를 다룬다.
클라이언트 응답 경로에서 Persistence Layer를 완전히 제거하여 Stateless한 응답을 구현했다.
1. 설계 원칙
1.1 기존 아키텍처의 문제
(1)편에서 scan_reward_task가 character-worker에서 실행되며 DB 조회와 gRPC 호출을 포함:
scan-worker character-worker
┌────────────────────────┐ ┌──────────────────────────────┐
│ scan.vision │ │ reward.character │
│ scan.rule │ │ │
│ scan.answer │ │ scan_reward_task │
│ │ │ │ ├── CharacterService (DB) │
│ └──────────────┼────▶│ └── sync_to_my (gRPC) │
└────────────────────────┘ └──────────────────────────────┘문제점:
- DB 장애 → 전체 Chain 실패
- gRPC 지연 → 응답 지연
- Worker 스케일링 = DB 부하 스케일링
1.2 목표: Stateless 응답 경로
응답 경로에서 DB 의존성을 완전히 제거:
┌──────────────────────────────────────────────────────────┐
│ Client Request Path (Stateless) │
│ │
│ scan.vision → scan.rule → scan.answer → scan.reward │
│ │ │ │ │ │
│ (OpenAI) (Local) (OpenAI) (Local Cache) │
│ │ │
│ ──────────┼─────▶ SSE Response
└──────────────────────────────────────────────────────────┘
│
Fire & Forget ───────┴─────────────┐
│
┌────────────────────────────────────────────────────────────▼───┐
│ Persistence Path (Eventually Consistent) │
│ │
│ character.save_ownership ──▶ character DB │
│ my.save_character ──▶ my DB │
└────────────────────────────────────────────────────────────────┘2. 아키텍처 변경 요약
| scan_reward_task 위치 | character-worker | scan-worker |
| 캐릭터 매칭 | CharacterService (DB) | Local Cache |
| my 도메인 동기화 | gRPC | 직접 DB INSERT |
| Worker 수 | 2개 | 4개 |
| Queue 타입 | Quorum | Classic |
| 응답 경로에 DB | 있음 | 없음 |
3. 파이프라인 구조
3.1 전체 흐름
Client ── POST /scan/classify/completion ──▶ scan-api
│
chain(vision | rule | answer | reward)
│
┌───────────────────────────────────────────────┼──────────────────────────────┐
│ RabbitMQ │
│ │
│ scan.vision ──▶ scan.rule ──▶ scan.answer ──▶ scan.reward │
│ │ │ │ │ │
│ (OpenAI) (Local) (OpenAI) character.match (동기) │
│ │ │
│ (Local Cache) │
│ │ │
│ ┌─────────────┴─────────────┐ │
│ ▼ ▼ │
│ character.reward my.reward │
│ (Fire&Forget) (Fire&Forget) │
└──────────────────────────────────────────────────────────────────────────────┘3.2 Worker 배포
| scan-worker | scan.vision, scan.rule, scan.answer, scan.reward | AI 호출 (긴 작업) | worker-ai |
| character-match-worker | character.match | 동기 응답 (짧은 작업) | worker-storage |
| character-worker | character.reward | Fire&Forget (배치) | worker-storage |
| my-worker | my.reward | Fire&Forget (배치) | worker-storage |
character.match 분리 이유:
character.reward는 배치 저장으로 수 초 블로킹character.match는 10초 타임아웃으로 빠른 응답 필요- 동기 응답(match)과 Fire&Forget(reward)의 특성이 상이
4. Queue 구성
4.1 Classic Queue 선택 근거
| HA (3+ 노드 필요) | 단일 노드 OK |
| global_qos 미지원 | global_qos 지원 |
단일 노드 RabbitMQ에서 Quorum의 이점이 없고, Celery 호환성을 고려하여 Classic Queue 채택.
4.2 Queue 명세
| scan.vision | 1h | dlq.scan.vision | GPT Vision |
| scan.rule | 5m | dlq.scan.rule | RAG 매칭 |
| scan.answer | 1h | dlq.scan.answer | GPT 답변 |
| scan.reward | 1h | dlq.scan.reward | 보상 dispatch |
| character.match | 30s | dlq.character.match | 동기 매칭 |
| character.reward | 24h | dlq.character.reward | 배치 저장 |
| my.reward | 24h | dlq.my.reward | 배치 저장 |
5. scan.reward Task
5.1 처리 흐름
@celery_app.task(name="scan.reward", queue="scan.reward")
def scan_reward_task(self, prev_result: dict) -> dict:
"""
Flow:
1. 조건 검증 (_should_attempt_reward)
2. character.match 호출 (동기 대기, 10초)
3. 클라이언트 응답 구성
4. save_ownership, save_character 발행 (Fire&Forget)
"""
if _should_attempt_reward(classification_result, disposal_rules, final_answer):
# 동기 호출 (Local Cache에서 매칭)
reward = _dispatch_character_match(user_id, classification_result, ...)
# Fire&Forget (DB 저장, 응답에 영향 없음)
if reward and reward.get("character_id"):
_dispatch_save_tasks(user_id, reward)
return {..., "reward": reward_response}5.2 gRPC 제거
기존 gRPC 기반 동기화는 직접 DB INSERT로 변경:
# Before: gRPC 호출
sync_to_my_task.delay(user_id, character)
# After: 직접 DB INSERT (Fire&Forget)
celery_app.send_task("my.save_character", kwargs={...}, queue="my.reward")이점:
- 장애 격리 (my DB 장애 → my-worker만 영향)
- 지연 감소 (gRPC 오버헤드 제거)
6. Celery Events 아키텍처
6.1 개요
Celery Events는 Worker의 Task 실행 상태를 실시간으로 브로드캐스트한다. 이를 SSE(Server-Sent Events)로 클라이언트에 스트리밍하여 Pipeline 진행상황을 제공한다.
┌────────────────────────────────────────────────────────────────────────────┐
│ Celery Events Flow │
│ │
│ Worker RabbitMQ API Server │
│ ┌────────┐ ┌───────────┐ ┌────────────┐ │
│ │ Task │──send_event──▶│ celeryev │◀──consume────│ Event │ │
│ │ 실행 │ │ exchange │ │ Receiver │ │
│ └────────┘ └───────────┘ └─────┬──────┘ │
│ │ │
│ asyncio.Queue │
│ │ │
│ ┌─────▼──────┐ │
│ │ SSE Stream │ │
│ │ Generator │ │
│ └─────┬──────┘ │
│ │ │
│ StreamingResponse │
│ │ │
│ Client │
└────────────────────────────────────────────────────────────────────────────┘6.2 이벤트 유형
| 이벤트 | 발생 시점 | 주요 필드 |
|---|---|---|
task-sent |
Task 발행 시 | uuid, name, root_id |
task-received |
Worker 수신 시 | uuid, name, hostname |
task-started |
실행 시작 시 | uuid, pid |
task-succeeded |
성공 완료 시 | uuid, result (str) |
task-failed |
실패 시 | uuid, exception |
task-result |
커스텀 | task_id, result (dict) |
6.3 EventReceiver 구현
별도 스레드에서 Celery Connection을 유지하며 이벤트를 수신:
def run_event_receiver() -> None:
"""Celery Event Receiver (별도 스레드)."""
from celery.events.receiver import EventReceiver
class ReadyAwareReceiver(EventReceiver):
"""Consumer 준비 완료 시점을 정확히 알려주는 Receiver."""
def __init__(self, *args, ready_event=None, **kwargs):
super().__init__(*args, **kwargs)
self.ready_event = ready_event
def consume(self, limit=None, timeout=None, safety_interval=1, **kwargs):
"""Consumer context 진입 후 ready 신호를 보내는 consume."""
with self.consumer():
self.ready_event.set() # Consumer 준비 완료 신호
# ... 이벤트 수신 루프 ...
with celery_app.connection() as connection:
recv = ReadyAwareReceiver(
connection,
handlers={
"task-sent": on_task_sent,
"task-received": on_task_received,
"task-started": on_task_started,
"task-succeeded": on_task_succeeded,
"task-failed": on_task_failed,
"task-result": on_task_result, # 커스텀 이벤트
},
ready_event=receiver_ready,
)
recv.capture(limit=None, timeout=120, wakeup=True)6.4 Chain Task 필터링
여러 Chain이 동시 실행될 수 있으므로 현재 요청의 Chain에 속한 이벤트만 처리:
chain_task_ids: set[str] = {task_id} # root task ID로 초기화
task_name_map: dict[str, str] = {} # task_id → task_name 매핑
def _is_chain_task(event: dict) -> bool:
"""이벤트가 현재 chain의 task인지 확인."""
event_task_id = event.get("uuid", "")
root_id = event.get("root_id")
parent_id = event.get("parent_id")
is_chain = (
root_id == task_id # 동일 root
or event_task_id == task_id # root task 자체
or event_task_id in chain_task_ids # 이미 추적 중
or parent_id in chain_task_ids # 부모가 추적 중
)
if is_chain:
chain_task_ids.add(event_task_id)
if event.get("name"):
task_name_map[event_task_id] = event.get("name")
return is_chain6.5 Progress 매핑
Task 이름을 클라이언트 친화적 단계명과 진행률로 변환:
TASK_STEP_MAP = {
"scan.vision": {"step": "vision", "progress": 25, "prev_progress": 0},
"scan.rule": {"step": "rule", "progress": 50, "prev_progress": 25},
"scan.answer": {"step": "answer", "progress": 75, "prev_progress": 50},
"scan.reward": {"step": "reward", "progress": 100, "prev_progress": 75},
}
def _send_sse_event(task_name: str, status: str, result: dict = None) -> None:
step_info = TASK_STEP_MAP.get(task_name, {})
progress = (
step_info["progress"] if status == "completed"
else step_info.get("prev_progress", 0)
)
sse_data = {"step": step_info["step"], "status": status, "progress": progress}
if task_name == "scan.reward" and status == "completed":
sse_data["result"] = _parse_celery_result(result)
loop.call_soon_threadsafe(event_queue.put_nowait, sse_data)6.6 커스텀 task-result 이벤트
문제: task-succeeded 이벤트의 result 필드는 Python repr 문자열로 전달되어 JSON 파싱이 불안정:
# task-succeeded 이벤트의 result (문자열)
"{'task_id': 'xxx', 'classification_result': {...}}"
# 홑따옴표, None, True/False 등으로 json.loads 실패해결: scan_reward_task에서 커스텀 이벤트를 직접 발행하여 dict 원본 전달:
# scan_reward_task 종료 시 발행
self.send_event(
"task-result",
result=result, # dict 그대로 전달
task_id=task_id,
root_id=task_id,
)Receiver에서 task-succeeded 대신 task-result 처리:
def on_task_succeeded(event: dict) -> None:
task_name = task_name_map.get(event.get("uuid", ""), "")
# scan.reward는 task-result 커스텀 이벤트에서 처리
if task_name == "scan.reward":
return # 무시
def on_task_result(event: dict) -> None:
"""커스텀 이벤트 - scan.reward 완료 결과."""
if event.get("root_id") != task_id:
return
# dict로 정확히 전달됨
_send_sse_event("scan.reward", "completed", result=event.get("result"))6.7 SSE 스트림 생성
ThreadPoolExecutor로 EventReceiver 스레드를 관리하고, asyncio.Queue로 이벤트 전달:
async def _completion_generator(...) -> AsyncGenerator[str, None]:
event_queue: asyncio.Queue[dict | None] = asyncio.Queue()
receiver_ready = threading.Event()
# 1. EventReceiver 백그라운드 실행
executor = ThreadPoolExecutor(max_workers=1)
future = executor.submit(run_event_receiver)
# 2. Consumer 준비 대기 (최대 5초)
if not receiver_ready.wait(timeout=5.0):
logger.warning("event_receiver_connect_timeout")
# 3. Chain 시작
chain(...).apply_async(task_id=task_id, ...)
yield _format_sse({"status": "started", "task_id": task_id})
# 4. 이벤트 스트리밍
while True:
try:
event = await asyncio.wait_for(event_queue.get(), timeout=1.0)
if event is None:
break
yield _format_sse(event)
if event.get("step") == "reward" and event.get("status") == "completed":
break
except asyncio.TimeoutError:
yield ": keepalive\n\n" # SSE keep-alive6.8 SSE 출력 예시
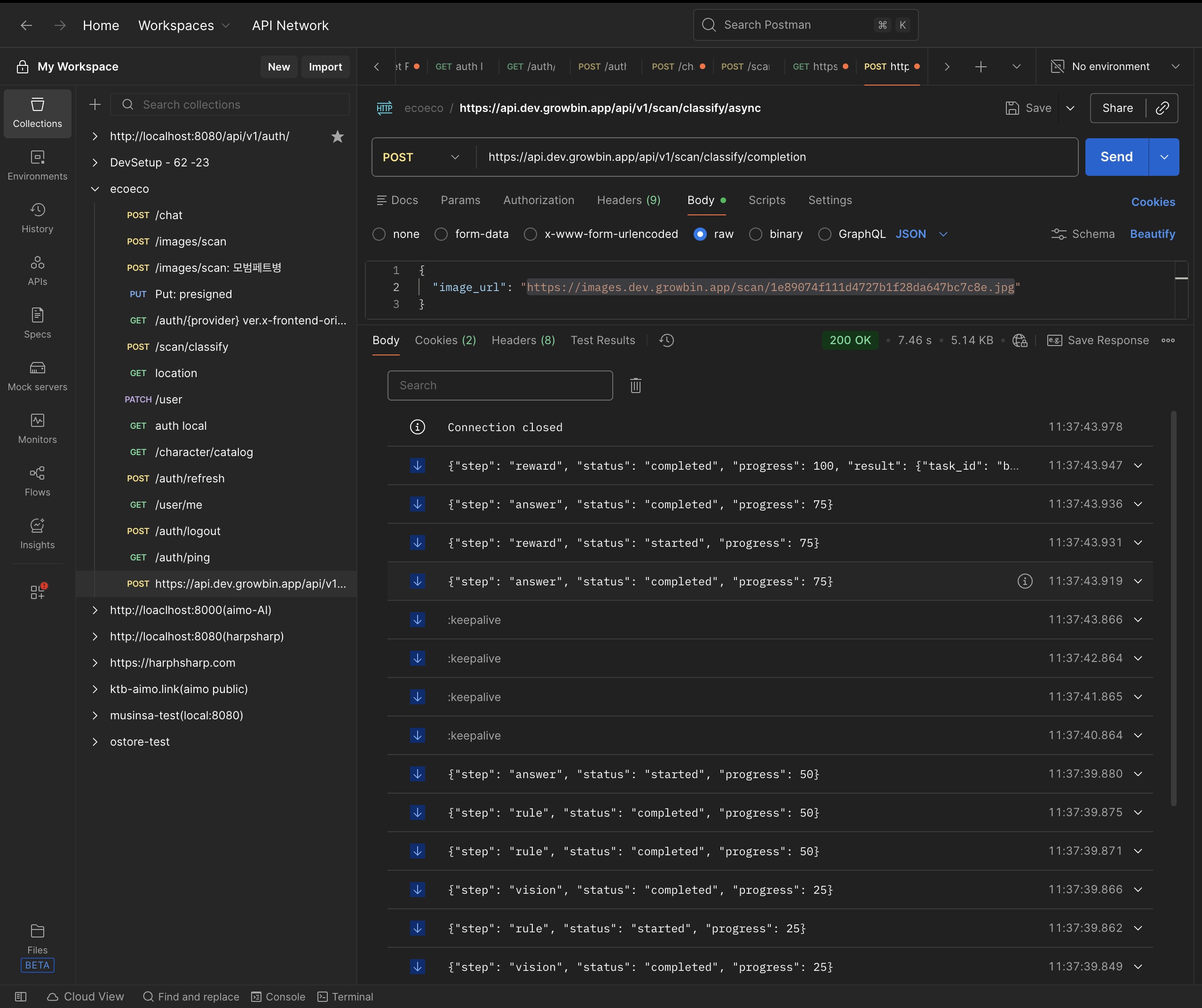
Scan API SSE 동작 모습이다. Scan API와 클라이언트가 연결되어 실시간으로 진행 이벤트를 수신하는 걸 확인할 수 있다.
(1080p 권장, 720p 화질 깨짐, vision -> rule -> answer -> reward 순으로 이벤트가 내려오는 걸 확인.)
RDB 레이어가 분리되면서 LLM 파이프라인 4스텝(캐릭터 보상 매칭 포함)의 단일 응답 시간이 8-10s에서 매칭까지 7s로 개선됐다.
모든 작업이 큐잉 및 Async 친화적으로 개편됐기에 보다 유연하게 동시접속 유저를 확보할 수 있을 걸로 예상된다.
큐잉+ Async SSE LLM API 개발이 완료되면 테스트한 이후 동기 API 당시의 지표와 비교해봐도 좋겠다.
7. Trade-off
| Classic Queue | Celery 호환 | Quorum HA 없음 |
| Worker 4개 분리 | 독립 스케일링, 장애 격리 | 운영 복잡도 |
| Fire&Forget | 응답 속도 | Eventual Consistency |
| gRPC 제거 | 단순화 | 타입 안전성 감소 |
References
- Celery Canvas: Designing Work-flows
- Celery Events: Real-time Monitoring
- Celery Custom Events
- RabbitMQ Classic vs Quorum Queues
- SSE (Server-Sent Events) - MDN