이코에코(Eco²)/Event Streams & Scaling
이코에코(Eco²) Streams & Scaling for SSE #4: KEDA 기반 이벤트 드리븐 오토스케일링
mango_fr
2025. 12. 26. 17:51
k6 부하 테스트 결과를 기반으로 KEDA와 Prometheus Adapter를 활용한 스케일링 전략을 수립하고 적용합니다.
Redis Streams 적용, 50VU 기준 Success Rate 86.3% (직전 테스트 Success Rate: 35%)
1. 배경: CPU 기반 HPA의 한계
문제 상황
기존 Kubernetes HPA(Horizontal Pod Autoscaler)는 CPU/Memory 사용률 기반으로 동작합니다.
# 기존 HPA (CPU 기반)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70문제: Scan Worker는 I/O-bound 워크로드다.
┌─────────────────────────────────────────────────────────────────┐
│ scan-worker 리소스 사용량 (k6 50 VU 테스트 중) │
├─────────────────────────────────────────────────────────────────┤
│ CPU: 37m / 1000m (3.7%) ← CPU 거의 미사용 │
│ Memory: 199Mi / 1Gi (19.4%) ← 메모리도 여유 │
│ │
│ 실제 병목: OpenAI API 대기 (6~10초/요청) │
└─────────────────────────────────────────────────────────────────┘CPU 사용률이 낮아 HPA가 트리거되지 않지만, RabbitMQ 큐에는 메시지가 쌓이는 상황이 발생한다.
해결 방향
| 워크로드 | 특성 | 스케일링 기준 | 도구 |
|---|---|---|---|
| scan-worker | I/O-bound (OpenAI API) | RabbitMQ 큐 길이 | KEDA |
| scan-api | SSE 연결 유지 | 활성 SSE 연결 수 | Prometheus Adapter + HPA |
2. KEDA (Kubernetes Event-driven Autoscaling)
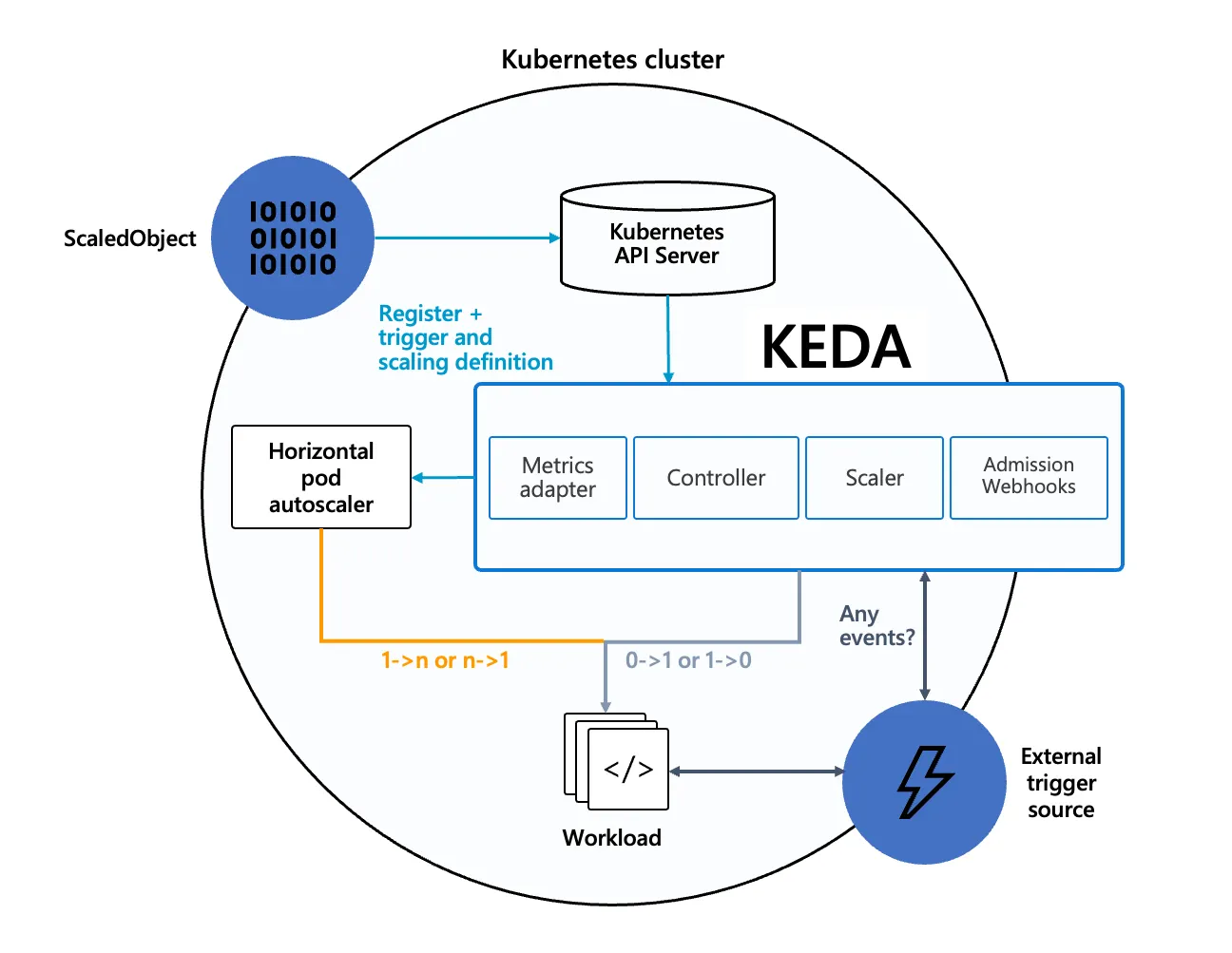
KEDA란?
KEDA는 이벤트 소스(RabbitMQ, Kafka, Redis 등)를 기반으로 Kubernetes 워크로드를 스케일링하는 오픈소스 프로젝트다.
┌─────────────────────────────────────────────────────────────────┐
│ KEDA 아키텍처 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌────────────┐ ┌────────────────────────┐ │
│ │ RabbitMQ │───▶│ KEDA │───▶│ HPA │ │
│ │ Queue │ │ Operator │ │ (자동 생성) │ │
│ └──────────┘ └────────────┘ └────────────────────────┘ │
│ │ │ │
│ │ 메시지 10개 이상 │ │
│ └──────────────────────────────────────┤ │
│ ▼ │
│ ┌────────────────────────┐ │
│ │ scan-worker │ │
│ │ replicas: 1 → 3 │ │
│ └────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘핵심 개념
| 리소스 | 설명 |
|---|---|
| ScaledObject | 스케일링 대상과 트리거를 정의하는 CR |
| TriggerAuthentication | 외부 시스템 인증 정보 |
| ScaledJob | Job 기반 스케일링 (배치 처리용) |
3. 설치 및 구성
ArgoCD Application 정의
# clusters/dev/apps/35-keda.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: dev-keda
namespace: argocd
annotations:
argocd.argoproj.io/sync-wave: '35'
spec:
project: dev
source:
repoURL: https://kedacore.github.io/charts
chart: keda
targetRevision: 2.12.1
helm:
releaseName: keda
valuesObject:
metricsServer:
replicaCount: 1
operator:
replicaCount: 1
destination:
server: https://kubernetes.default.svc
namespace: keda
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=trueSync-wave 순서
24: PostgreSQL
25: Prometheus Adapter
27: Redis Operator
28: Redis Cluster (CRs)
...
35: KEDA ← 메트릭 시스템 이후
36: Scaling ← ScaledObject, HPA4. scan-worker ScaledObject
설계 원칙
- RabbitMQ 큐 길이 기반: 메시지가 쌓이면 스케일 아웃
- 다중 트리거: vision, answer, rule 큐 모두 모니터링
- 보수적 스케일 다운: 갑작스러운 축소 방지
ScaledObject 정의
# workloads/scaling/base/scan-worker-scaledobject.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: scan-worker-scaledobject
namespace: scan
spec:
scaleTargetRef:
name: scan-worker
kind: Deployment
# 스케일링 범위
minReplicaCount: 1
maxReplicaCount: 10
# 빠른 감지 & 스케일다운
cooldownPeriod: 30 # 60s → 30s
pollingInterval: 10 # 15s → 10s
# 고급 설정
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 120 # 2분간 안정화
policies:
- type: Percent
value: 50
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 0 # 즉시 스케일업
policies:
- type: Pods
value: 2
periodSeconds: 30
# RabbitMQ 트리거
triggers:
- type: rabbitmq
metadata:
protocol: amqp
queueName: scan.vision
mode: QueueLength
value: '10' # 10개 이상 → 스케일업
authenticationRef:
name: rabbitmq-trigger-auth
- type: rabbitmq
metadata:
protocol: amqp
queueName: scan.answer
mode: QueueLength
value: '10'
authenticationRef:
name: rabbitmq-trigger-auth
- type: rabbitmq
metadata:
protocol: amqp
queueName: scan.rule
mode: QueueLength
value: '20' # rule은 빠르므로 임계값 높게
authenticationRef:
name: rabbitmq-trigger-authTriggerAuthentication
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: rabbitmq-trigger-auth
namespace: scan
spec:
secretTargetRef:
- parameter: host
name: scan-secret
key: CELERY_BROKER_URL5. scan-api HPA (Prometheus Adapter)
Custom Metrics HPA
scan-api는 SSE 연결 수를 기준으로 스케일링합니다.
# workloads/scaling/base/scan-api-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: scan-api-hpa
namespace: scan
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: scan-api
minReplicas: 1
maxReplicas: 3
metrics:
# 커스텀 메트릭: SSE 활성 연결 수
- type: Pods
pods:
metric:
name: scan_sse_connections_active
target:
type: AverageValue
averageValue: "50" # Pod당 50개 연결
# 백업: Memory 사용률
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 5분 안정화
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Pods
value: 1
periodSeconds: 30Prometheus Adapter 설정
# clusters/dev/apps/25-prometheus-adapter.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: dev-prometheus-adapter
annotations:
argocd.argoproj.io/sync-wave: '25'
spec:
source:
repoURL: https://prometheus-community.github.io/helm-charts
chart: prometheus-adapter
targetRevision: 4.3.0
helm:
valuesObject:
prometheus:
url: http://kube-prometheus-stack-prometheus.prometheus:9090
rules:
custom:
- seriesQuery: '{__name__="scan_sse_connections_active"}'
resources:
template: <<.Resource>>
name:
matches: "scan_sse_connections_active"
as: "scan_sse_connections_active"
metricsQuery: sum(scan_sse_connections_active{namespace="scan"}) by (pod)6. NetworkPolicy 업데이트
KEDA가 RabbitMQ에 접근할 수 있도록 NetworkPolicy를 업데이트합니다.
# workloads/network-policies/base/allow-rabbitmq-access.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-rabbitmq-access
namespace: rabbitmq
spec:
podSelector:
matchLabels:
app.kubernetes.io/name: rabbitmq
ingress:
- from:
# KEDA에서 RabbitMQ 큐 조회 허용
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: keda
# scan-worker에서 메시지 처리
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: scan
ports:
- protocol: TCP
port: 56727. 모니터링
KEDA 상태 확인
# ScaledObject 상태
kubectl get scaledobject -n scan -o wide
# 생성된 HPA 확인
kubectl get hpa -n scan -o wide
# KEDA 로그
kubectl logs -n keda -l app=keda-operator --tail=50Grafana 대시보드 쿼리
# RabbitMQ 큐 길이
rabbitmq_queue_messages{queue=~"scan.*"}
# KEDA 스케일링 이벤트
keda_scaler_metrics_latency_seconds_bucket
# scan-worker Replica 수
kube_deployment_status_replicas{deployment="scan-worker"}8. k6 테스트 결과 기반 튜닝
k6 50 VU
| 지표 | 값 |
|---|---|
| Total Requests | 658 |
| Completed | 537 (81.6%) |
| Partial | 55 (8.4%) |
| Failed | 66 (10.0%) |
| Reward Null | 144 (21.9%) |
튜닝 포인트
| 항목 | Before | After | 이유 |
|---|---|---|---|
| cooldownPeriod | 60s | 30s | 빠른 스케일다운 |
| pollingInterval | 15s | 10s | 빠른 감지 |
| scaleDown.stabilization | 300s | 120s | 비용 최적화 |
| queueLength (rule) | 10 | 20 | rule은 빠름 |
Exponential Backoff 재시도
# domains/scan/tasks/vision.py
@celery_app.task(
bind=True,
max_retries=2,
default_retry_delay=1,
)
def vision_task(self, ...):
try:
result = analyze_images(...)
except Exception as exc:
# Exponential backoff: 1s, 2s, 4s
countdown = 2 ** self.request.retries
raise self.retry(exc=exc, countdown=countdown)Reward Fallback
# domains/scan/tasks/reward.py
def _dispatch_character_match(...):
try:
result = async_result.get(timeout=MATCH_TIMEOUT)
return result
except CeleryTimeoutError:
# Fallback: 전체 파이프라인 실패 방지
logger.warning("Character match timeout - returning fallback")
return None9. 결론
스케일링 전략 요약
┌─────────────────────────────────────────────────────────────────┐
│ Eco² 스케일링 아키텍처 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ scan-api scan-worker │
│ ┌──────────────────┐ ┌──────────────────┐ │
│ │ HPA │ │ KEDA │ │
│ │ (Prometheus │ │ (RabbitMQ │ │
│ │ Adapter) │ │ ScaledObject) │ │
│ └────────┬─────────┘ └────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ scan_sse_connections_active rabbitmq_queue_messages │
│ │
└─────────────────────────────────────────────────────────────────┘9. 적용 결과 검증
ArgoCD 동기화 상태
$ kubectl get applications -n argocd | grep -E 'scaling|redis-cluster|scan'
dev-api-scan Synced Healthy
dev-redis-cluster Synced Healthy
dev-scaling Synced Healthy
dev-scan-worker Synced HealthyKEDA 설정 적용 확인
$ kubectl get scaledobject scan-worker-scaledobject -n scan \
-o jsonpath='{.spec.cooldownPeriod} {.spec.pollingInterval}'
30 10 # ✅ cooldownPeriod=30, pollingInterval=10Redis Streams 메트릭 수집
$ kubectl exec -n prometheus prometheus-kube-prometheus-stack-prometheus-0 \
-c prometheus -- wget -qO- \
'http://localhost:9090/api/v1/label/__name__/values' | jq -r '.data[]' | grep redis_stream
redis_stream_first_entry_id
redis_stream_groups
redis_stream_last_entry_id
redis_stream_length # ✅ Stream별 이벤트 수 수집
redis_stream_radix_tree_keys
redis_stream_radix_tree_nodesPrometheus Stream 메트릭 샘플
{"stream": "scan:events:04299bb1-...", "length": "9"}
{"stream": "scan:events:0bb4a2b7-...", "length": "8"}
// 현재 35개 Stream 키 활성