-
이코에코(Eco²) Service Mesh #2: 내부 통신을 위한 gRPC 마이그레이션이코에코(Eco²)/Kubernetes Cluster+GitOps+Service Mesh 2025. 12. 12. 04:04
동기식 HTTP 통신의 한계와 아키텍처 전환의 필요성
지난 포스팅에서 다룬 Scan API 성능 분석 결과, LLM 파이프라인 중 Answer Model(GPT 5.1)이 주된 병목임을 확인했다. 하지만 LLM 모델의 병목은 API를 호출하는 입장에선 접근할 수 없다. 선택 가능한 방향인 서비스 간 통신의 효율성을 확보하는 게 최선이다.
현재 이코에코는
Scan->Character->Scan으로 이어지는 동기식 HTTP/1.1 호출 구조를 가지고 있다. 트래픽 증가 시 HTTP Connection Overhead와 JSON 직렬화 비용은 무시할 수 없는 Latency 요인이 되며, 진행 중인 Auth-Offloading(Envoy ext_authz) 도입을 위해서도 내부 통신 인터페이스의 표준화(gRPC)가 요구된다.본 포스팅은 FastAPI 기반 마이크로서비스 환경에서 gRPC로 전환하며 수행한 아키텍처 설계와, Kubernetes + Istio + Calico 환경에서 진행한다.
내부 통신 프로토콜로서의 gRPC
마이크로서비스 아키텍처에서 외부 클라이언트는 범용적인 REST(HTTP/1.1)를, 내부 서비스 간에는 고성능 gRPC(HTTP/2)를 사용하는 이원화 전략은 표준에 가깝다. 이는 각 프로토콜의 기술적 특성에 기인한다.
gRPC란 무엇인가?
https://www.youtube.com/watch?v=sImWl7JyK_Q&t=1103s
gRPC는 Google에서 개발한 오픈소스 RPC(Remote Procedure Call) 프레임워크다.
마치 로컬 함수를 호출하듯(Call local function), 원격 서버의 함수를 호출할 수 있게 해주는 것이 RPC의 핵심 철학이다.
gRPC Core ComponentsgRPC는
Protocol Buffers의 IDL(Interface Definition Language) 역할과 직렬화(Serialization) 역할을 분리하여 이해해야 하며, 이를 전송하는HTTP/2프로토콜과의 결합을 통해 고성능 프로토콜을 구현한다.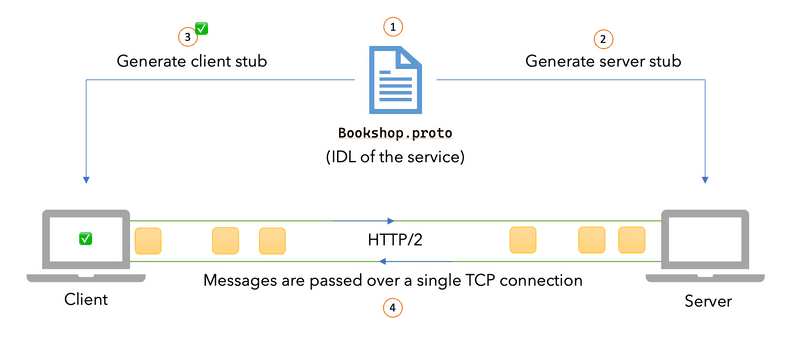
1. Protocol Buffers (IDL): 인터페이스 정의 및 스키마
Protobuf는 이기종 시스템(Polyglot) 간의 통신 규약을 정의하는 IDL로서 기능한다.
- Strict Typing & Schema Definition:
.proto파일을 통해 데이터 구조(Message)와 서비스 인터페이스(Service)를 명시적으로 정의한다. JSON과 같은 Schema-less 포맷이 가질 수 있는 타입 모호성을 제거하고, 컴파일 타임에 타입을 강제함으로써 런타임 에러를 방지한다. - Code Generation:
protoc컴파일러는 정의된 스키마를 기반으로 Python, Go, Java 등 각 언어에 최적화된 클라이언트(Stub)와 서버(Skeleton) 코드를 자동 생성한다. 이를 통해 API 명세와 구현 코드 간의 불일치(Drift) 문제를 해결하고 개발 생산성을 높인다.
2. Protocol Buffers (Serialization): 바이너리 직렬화
IDL이 인터페이스를 정의한다면, 직렬화 메커니즘은 데이터를 네트워크로 전송하기 위해 최적화된 형태로 변환한다.
- Binary Wire Format
텍스트 기반(JSON/XML)이 아닌 이진 데이터로 직렬화한다. 텍스트 파싱(Parsing) 과정이 생략되므로 CPU 오버헤드가 현저히 낮다. - TLV (Tag-Length-Value) Encoding
필드 이름(Key)을 문자열로 전송하는 대신,.proto에 선언된 Field Number(정수형 태그)를 사용하여 매핑한다. 불필요한 메타데이터 전송을 줄여 페이로드 크기를 최소화하고 네트워크 대역폭 효율을 극대화한다.
3. HTTP/2 (Transport): 전송 프로토콜
직렬화된 바이너리 데이터는 HTTP/2 프로토콜을 통해 전송된다.
- Multiplexing
단일 TCP 연결(Connection) 내에서 다수의 스트림(Stream)을 동시에 처리한다. HTTP/1.1의 HOL(Head-of-Line) Blocking 문제를 해결하고, 반복적인 TCP Handshake 비용을 절감한다. - Bidirectional Streaming
단일 연결에서 클라이언트와 서버가 양방향으로 데이터를 실시간 전송할 수 있는 스트리밍 기능을 네이티브로 지원한다. - Binary Framing
HTTP/2는 전송 단위를 텍스트가 아닌 바이너리 프레임으로 처리하므로, Protobuf의 바이너리 데이터 구조와 호환성이 높다.
HTTP/1.1 REST vs gRPC (Comparison)
가장 큰 차이는 연결을 다루는 방식과 데이터를 주고받는 형태다.
- HTTP/1.1 (REST):
- Text (JSON): 사람이 읽기 쉽지만, 파싱 비용이 크고 페이로드가 큶.
- Request/Response: 매 요청마다 연결(Connection) 비용이 발생하거나, HOL Blocking 문제로 병렬 처리에 한계가 있음.
- gRPC (HTTP/2):
- Binary (Protobuf): 작고 효율적. CPU 사용량이 적음.
- Streaming & Multiplexing: 하나의 TCP 연결 안에서 수많은 요청을 동시에, 비동기적으로 처리.
HTTP/1.1 (REST) - 순차적 처리와 연결 비용
요청마다 연결을 맺거나(Handshake), 앞선 요청이 끝나야 다음 요청을 처리한다(HOL Blocking).

gRPC (HTTP/2) - 멀티플렉싱과 효율성
한 번의 연결(Handshake) 후, 하나의 파이프라인 안에서 여러 요청(Stream)이 동시에 오고 가는 구조.

기술적 이점
gRPC 도입의 핵심 근거는 HTTP/2의 전송 효율성과 Protobuf의 엄격함이다.
- Connection Multiplexing (HTTP/2): 단일 TCP 연결로 다수의 요청/응답 스트림을 처리하여 Handshake 오버헤드와 HOL(Head-of-Line) Blocking을 제거한다.
- Efficient Serialization (Protobuf): 텍스트 기반인 JSON 대비 바이너리 포맷을 사용하여 페이로드 크기를 줄이고, 직렬화/역직렬화에 소요되는 CPU 리소스를 절감한다.
- Strict Interface Contract (IDL):
.proto파일을 통해 서비스 간 인터페이스를 명확히 정의함으로써, 컴파일 타임에 타입 불일치를 방지하고 통신 규약을 강제한다.
이러한 특성은 서비스 간 호출 빈도가 높고 낮은 지연 시간(Low Latency)이 요구되는 내부 통신 환경에 최적화되어 있다.
K8s에서 gRPC를 쓸 때 마주하는 트래픽 불균형
Scan 서비스에서 Character 서비스로의 보상 로직은 이코에코의 메인 기능인 scna과 연동돼 빈번하게 호출되는 가벼운 트랜잭션이다. 기존 HTTP/1.1 환경에서는 매 요청마다 TCP Handshake가 발생하나, gRPC 도입으로 연결 비용(Connection Overhead)을 제거할 수 있다.
하지만 gRPC의 Long-lived Connection(장기 지속 연결)은 Kubernetes의 기본 네트워크 모델인 Service(L4 Load Balancer)와 만났을 때, 트래픽 불균형(Imbalance) 문제를 야기한다.문제의 발단: L4 로드밸런싱의 한계 (East-West)
Kubernetes의
Service(ClusterIP)는 L4(Transport Layer, TCP/IP) 계층에서 동작한다. 즉, 로드밸런싱의 기준이 "연결(Connection)을 누구와 맺을 것인가?"에 있다.- HTTP/1.1의 경우: 클라이언트가 요청을 보낼 때마다 연결을 맺고 끊는다. K8s Service는 새로운 연결 시도마다 라운드 로빈으로 파드를 배정하니, 자연스럽게 트래픽이 여러 파드에 분산된다.
- gRPC (HTTP/2)의 경우: 효율성을 위해 클라이언트(Scan)와 서버(Character)가 최초 한 번 TCP 연결을 맺고, 이 연결을 끊지 않은 채 수천, 수만 개의 요청(Stream)을 지속적으로 보낸다.
불균형 시나리오
이 차이로 인해 다음과 같은 시나리오가 발생한다.
Scan-Pod가 시작되면서Character-Service로 gRPC 연결을 시도한다.- K8s Service는 이 연결 요청을
Character-Pod-A에게 전달한다. (Connection Established) - 이후
Scan-Pod에서 발생하는 모든 보상 요청 트래픽은 이미 뚫려 있는 이 하나의 파이프를 통해서만Character-Pod-A로 집중된다. - 트래픽이 집중되어
Character-Pod-B,Character-Pod-C로 오토스케일링(HPA)이 일어나도 영향을 받지 못한다. 새로운 연결(Connection)이 발생하지 않기 때문에, K8s Service는 새 파드들에게 트래픽을 나눠줄 기회조차 얻지 못한다. - 결국
Character-Pod-A혼자서 모든 부하를 감당하다가 OOM(Out of Memory)으로 죽고, 연결이 끊기면 그제야 다른 파드로 연결이 넘어가는 악순환이 반복된다.
Istio(Envoy)를 통한 L7 로드밸런싱 (East-West)
이 문제를 해결하려면 연결 단위가 아닌, 요청(RPC Request) 단위로 부하를 분산해야 한다. 이를 위해서는 프로토콜 내부를 들여다볼 수 있는 L7 로드밸런서가 필요하다.
이코에코는 Istio Service Mesh를 활용해, 서버에 별도의 로드벨런싱 코드를 주입하지 않고 인프라 레벨에서 해결했다.- Envoy Sidecar의 역할: 각 파드에 주입된 Envoy 프록시는 gRPC(HTTP/2) 프로토콜을 인지한다.
- Request-level Balancing:
Scan파드에서 나가는 gRPC 요청을 Envoy가 가로챈다. Envoy는 백엔드의 모든Character파드들과 미리 커넥션 풀을 유지하고 있다가, 들어오는 요청들을 하나씩 쪼개어(Demultiplexing) 파드들에게 고르게 분산시킨다.
결과적으로 복잡한 로드밸런싱 로직을 신경 쓸 필요 없이 서버엔 비즈니스 로직 구현만 남고, 인프라(Istio)가 gRPC 트래픽의 균형을 완벽하게 보장해주는 구조가 완성됐다.
FastAPI와 gRPC의 공존 전략
Python 생태계에서 gRPC 도입 시 가장 큰 고민은 기존 웹 프레임워크(FastAPI)와의 통합 구조다.
단일 프로세스 vs 프로세스 분리 (FastAPI)

REST 파드와 gRPC 파드가 개별로 동작 중인 걸 확인할 수 있다. 두 서버 모두 Envoy Sidecar와 함께 배포되기에 2/2인 상태다.
기능 개발과 공통 Observability에 중점을 둔다면 하나의 프로세스 내에서 FastAPI(HTTP)와 gRPC 서버를 동일 프로세스에서 구동하는 방안을 고려할 수 있다. 그렇지만 Go처럼 goroutine과 Runtime Scheduler를 지원하지 않는 상황에서 FastAPI 단일 프로세스로 관리하는 일에는 많은 제약사항이 따른다. 차후 Go 기반 ext-authz 개발기에서도 가볍게 언급되는 파트지만, FastAPI와 Go를 비교하며 두 언어에서 HTTP와 gRPC를 운용할 때 어떤 구조가 더 합리적인지 논의해 보자.
리소스 격리 및 스케일링
Go vs Python의 동시성 모델과 프로세스 분리 당위성
Go 기반 서비스의 경우, 단일 파드 내에서 REST 서버와 gRPC 서버를 goroutine으로 동시에 구동하는 것이 일반적이다.
반면 Python 기반 서비스에서는 프로세스(파드) 레벨의 분리를 선택했다. 이는 두 언어의 근본적인 런타임 특성 차이에서 기인한다.리소스 경합
스케줄링 계층 비교
스케줄링 위치 User-space (Go Runtime) Kernel-space (OS) 스케줄러 개수 1개 (통합) N개 (uvicorn + grpcio + ...) 컨텍스트 스위칭 ~200ns (goroutine 전환) ~1-10μs (OS 스레드 전환) 전환 비용 레지스터 몇 개 저장 전체 스레드 상태 저장 + 커널 모드 전환 Go: Cooperative + Preemptive 하이브리드 스케줄링
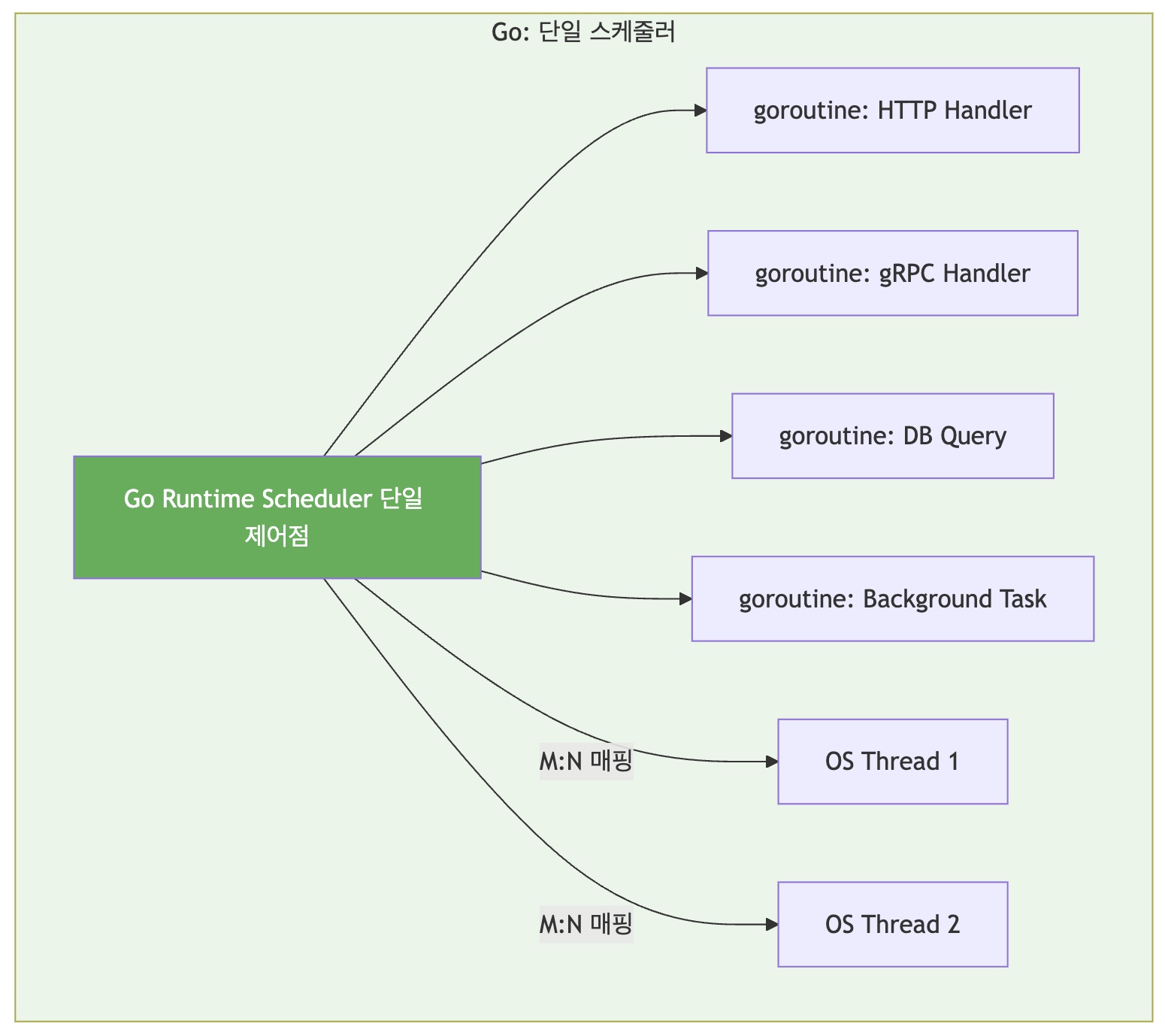
Go의 경우 Runtime Scheduler에서 goroutine을 병렬로 스케줄링 // Go Runtime이 모든 goroutine을 "알고 있음" // → 지능적인 스케줄링 가능 func httpHandler() { // I/O 대기 시 자동으로 다른 goroutine에게 양보 resp, _ := http.Get("...") // 여기서 스케줄러가 전환 결정 } func grpcHandler() { // 동일한 스케줄러가 관리 // → HTTP와 gRPC 간 공정한 CPU 배분 }
Go Runtime의 작동 방식- goroutine은 user-space 레벨의 경량 스레드로 동작
- Runtime Scheduler로 모든 goroutine의 상태를 한 곳에서 파악 (OS 관점에서 동일한 스레드)
- I/O 블로킹 시 즉시 다른 goroutine으로 전환
- CPU-bound 작업도 주기적으로 preemption
- Work-stealing으로 OS 스레드 간 부하 균등 분배
- 때문에 Go에서는 동일 프로세스, 개별 goroutine으로 REST, gRPC 멀티서버를 운용하는 게 표준 (etc. CNCF projects)
Python: 독립적인 스레드 풀들의 경쟁

런타임 스케줄러가 없기 때문에 OS Kernel Scheduler에게 의존, 빈번한 커널 접근으로 컨택스트 스위칭 오버헤드 발생 # uvicorn: 자체 스레드 풀 운영 # grpcio: 자체 C-extension 스레드 풀 운영 # → 서로의 존재를 "모름" async def http_handler(): # uvicorn의 event loop에서 실행 await some_io() def grpc_handler(): # grpcio의 스레드 풀에서 실행 # uvicorn과 CPU 시간을 OS 레벨에서 경쟁
Python의 문제점- uvicorn 스레드 풀: "나는 바쁘다" → OS에 CPU 요청
- grpcio 스레드 풀: "나도 바쁘다" → OS에 CPU 요청
- Kernel 레벨에서 스케줄링(OS) 진행
- OS 측에선 별개의 스레드로 인지해 스케줄링 오버헤드 비용 큼
- 불필요한 컨텍스트 스위칭, 캐시 미스 증가
메모리 계층 비교
초기 스택 크기 ~2KB 1-8MB 1000개 생성 시 메모리 ~2MB 1-8GB 메모리 할당자 단일 (Go runtime) 다중 (Python + C) GC 조율 통합 관리 독립적 (경쟁)
캐시 효율성
Go에서는 동일한 OS 스레드에서 여러 goroutine이 순차 실행되므로 CPU 캐시가 유지된다.
Python에서는 OS가 스레드를 전환할 때마다 캐시 플러시가 발생한다.
REST, gRPC 프로세스 분리 (FastAPI)
OS 상에서 별개 스레드로 동작하고 GIL로 다중 스레드 간 병렬 운행에 제약이 있는만큼,
Python에선 동일 프로세스, 멀티 스레드 서버로 운용할 때 얻는 이점이 적다.
때문에 프로세스를 분리해 REST와 gRPC를 별개의 파드로 가져가는 방향을 택했다.
책임 분리
앞선 과정을 통해 FastAPI에서 REST와 gRPC를 별개 프로세스로 분할하는 근거들을 살펴봤다.
그로 인해 REST 엔드포인트는 클라이언트 요청 검증 및 응답 포맷팅에 집중하고, gRPC 서버는 핵심 비즈니스 로직 수행에 집중한다.
이는 MQ 도입 시 Consumer 역할을 gRPC 서비스가 자연스럽게 흡수할 수 있는 구조적 기반이 된다.계층별 역할 분리
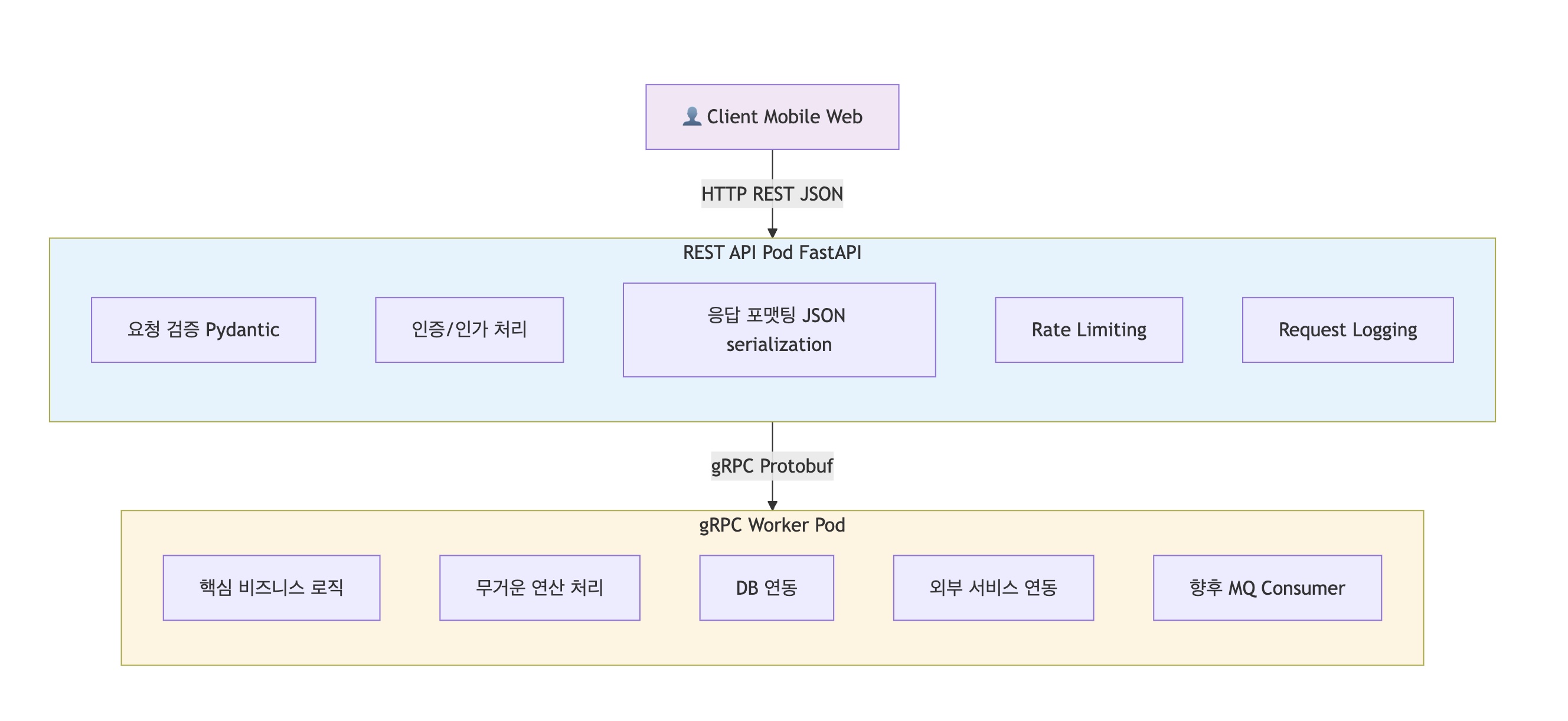
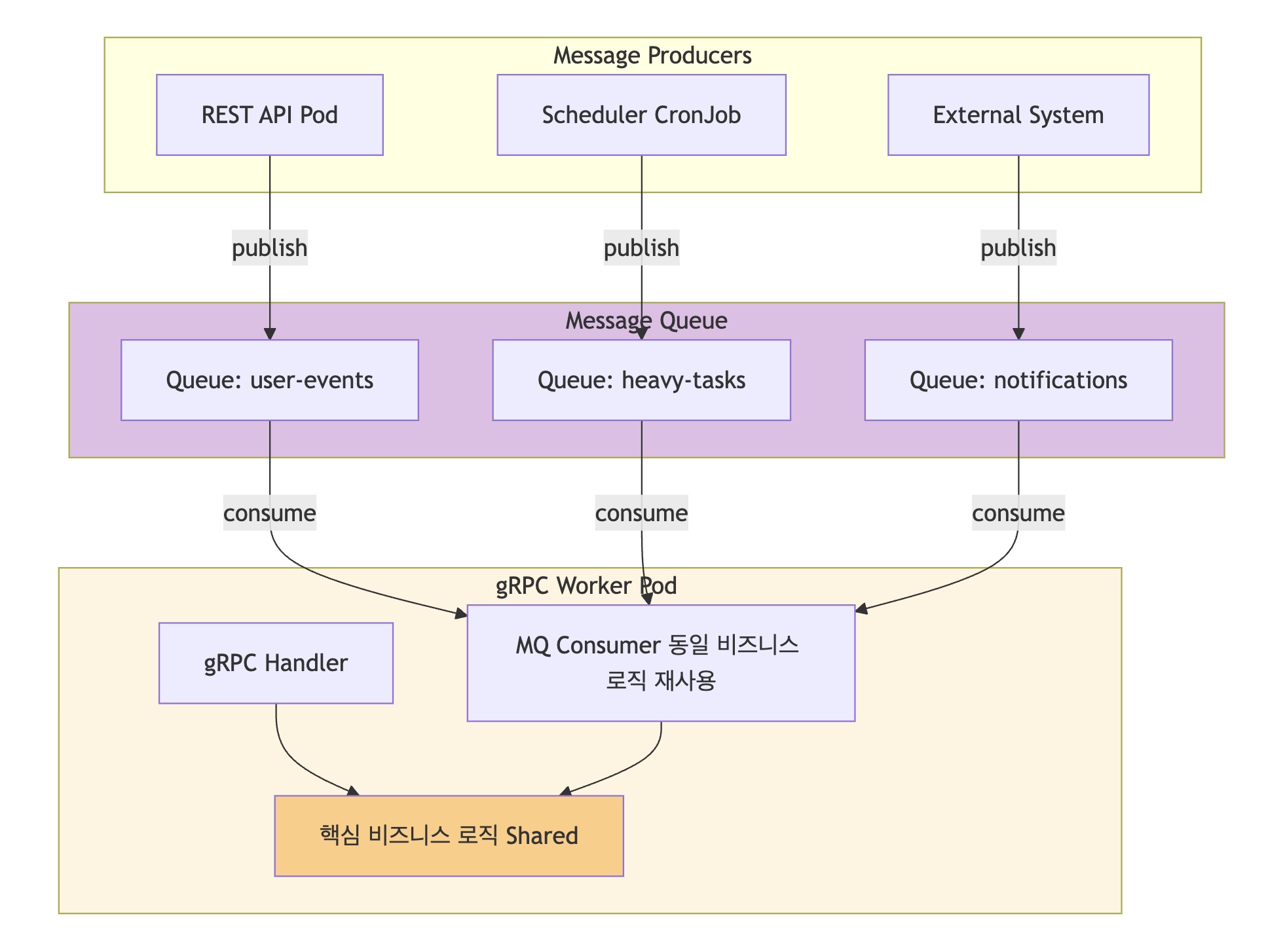
현재의 분리 구조는 Message Queue 도입 시 자연스러운 확장 경로를 제공한다.
gRPC 서버가 비즈니스 로직 실행자로서 역할을 담당하고 있기 때문에 MQ Consumer 로직을 추가하는 것이 일관성 있는 확장이 된다.
레이어드 아키텍처(Layered Architecture)의 활용
프로세스가 분리되더라도 비즈니스 로직의 중복은 최대한 기피해야 한다.- Service Layer
- 핵심 비즈니스 로직을 담고 있으며, 프로토콜(HTTP/gRPC)에 종속되지 않는 순수 Python 객체로 구현한다.
- Presentation Layer:
- REST Controller (FastAPI Router): HTTP 요청을 받아 Service Layer를 호출.
- gRPC Servicer: gRPC 요청을 받아 동일한 Service Layer를 호출.
이 구조를 통해 통신 프로토콜이 변경되거나 추가되더라도, 핵심 로직인 Service Layer는 수정 없이 재사용 가능하다.
Implementation
1. Proto 정의 (IDL)
먼저 두 서비스(
Scan,Character)가 소통할 표준을 정의한다.character.proto에 요청/응답 메시지와 RPC 서비스를 명세했다.// domains/character/proto/character.proto syntax = "proto3"; package character.v1; service CharacterService { rpc GetCharacterReward (RewardRequest) returns (RewardResponse) {} } message RewardRequest { string source = 1; string user_id = 2; string task_id = 3; // ... (생략) } message RewardResponse { bool received = 1; string name = 2; // ... (생략) }2. Service Layer (비즈니스 로직)
비즈니스 로직은 프로토콜(REST/gRPC)을 전혀 모르게 설계했다.
순수한 Python 객체(
CharacterRewardRequest)를 받아 처리한다.# domains/character/services/character.py class CharacterService: async def evaluate_reward(self, payload: CharacterRewardRequest) -> CharacterRewardResponse: # 1. 캐릭터 매칭 로직 # 2. 보상 지급 및 DB 저장 # 3. 결과 반환 return self._to_reward_response(...)3. gRPC Servicer (Server Implementation)
Character서비스의 gRPC 서버 구현부다. Protobuf 요청을 받아 Pydantic 모델로 변환한 후, 위에서 정의한CharacterService를 호출한다. 여기서 유의할 점은 DB 세션 관리다. FastAPI의Depends를 쓸 수 없으므로, Context Manager로 세션을 관리했다.# domains/character/rpc/v1/character_servicer.py class CharacterServicer(character_pb2_grpc.CharacterServiceServicer): async def GetCharacterReward(self, request, context): try: # 1. Protobuf -> Pydantic 변환 payload = CharacterRewardRequest( user_id=UUID(request.user_id), # ... ) # 2. 비즈니스 로직 호출 (Service Layer 재사용) async with async_session_factory() as session: service = CharacterService(session) result = await service.evaluate_reward(payload) # 3. Pydantic -> Protobuf 변환 및 반환 return character_pb2.RewardResponse( received=result.received, name=result.name, # ... ) except Exception as e: await context.abort(grpc.StatusCode.INTERNAL, str(e))4. gRPC Client (Scan Service)
Scan서비스에서는 기존httpx코드를 걷어내고, gRPC Stub을 호출하도록 변경했다.Scan 서비스에서는 gRPC Stub을 호출할 때 싱글톤 패턴을 적용했다. Connection Multiplexing을 활용하고자 매 요청마다 연결을 맺고 끊는 대신, 하나의 객체로 TCP 연결을 유지하며 수천 개의 요청을 동시에 흘려보냄으로써 핸드셰이크 비용과 소켓 리소스를 절약했다.
# domains/scan/core/grpc_client.py _channel = None _stub = None async def get_character_stub(): global _channel, _stub if _stub is None: # K8s Service 주소 (ClusterIP)로 연결 target = "character-grpc.character.svc.cluster.local:50051" _channel = grpc.aio.insecure_channel(target) _stub = character_pb2_grpc.CharacterServiceStub(_channel) return _stub # domains/scan/services/scan.py async def _call_character_reward_api(self, request): stub = await get_character_stub() grpc_req = character_pb2.RewardRequest(...) # gRPC 호출 (네트워크 구간) response = await stub.GetCharacterReward(grpc_req, timeout=5.0) return CharacterRewardResponse(received=response.received, ...)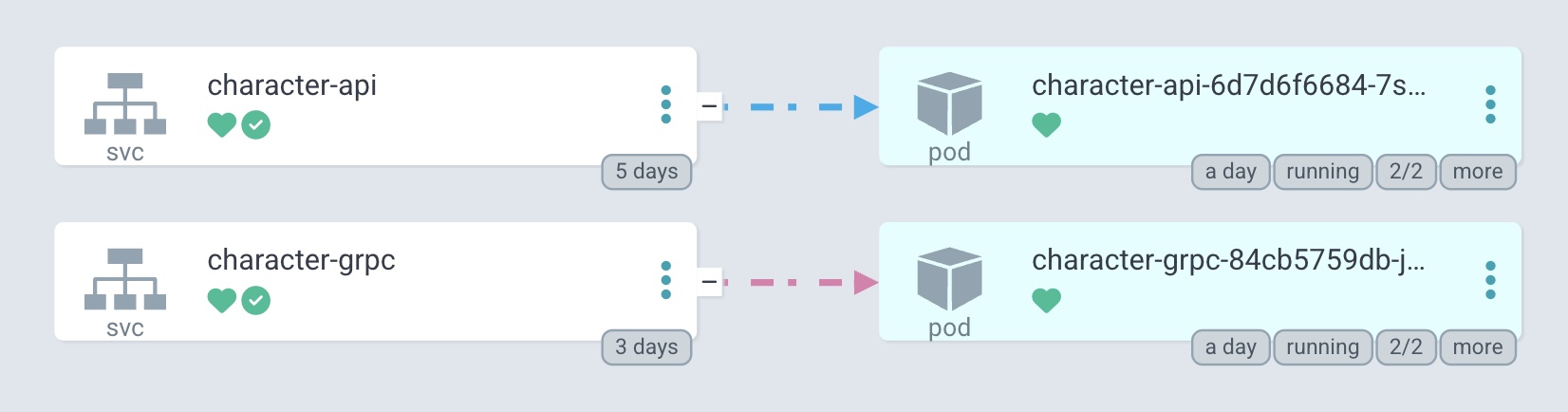
이로써 REST 컨트롤러와 gRPC Servicer가 분리되었고,
비즈니스 로직의 중복 없이 두 프로토콜을 동일 도메인, 개별 파드로 지원할 수 있게 되었다.
Performance: 전환 효과 및 데이터
Latency (user 10, ramp-up 1)
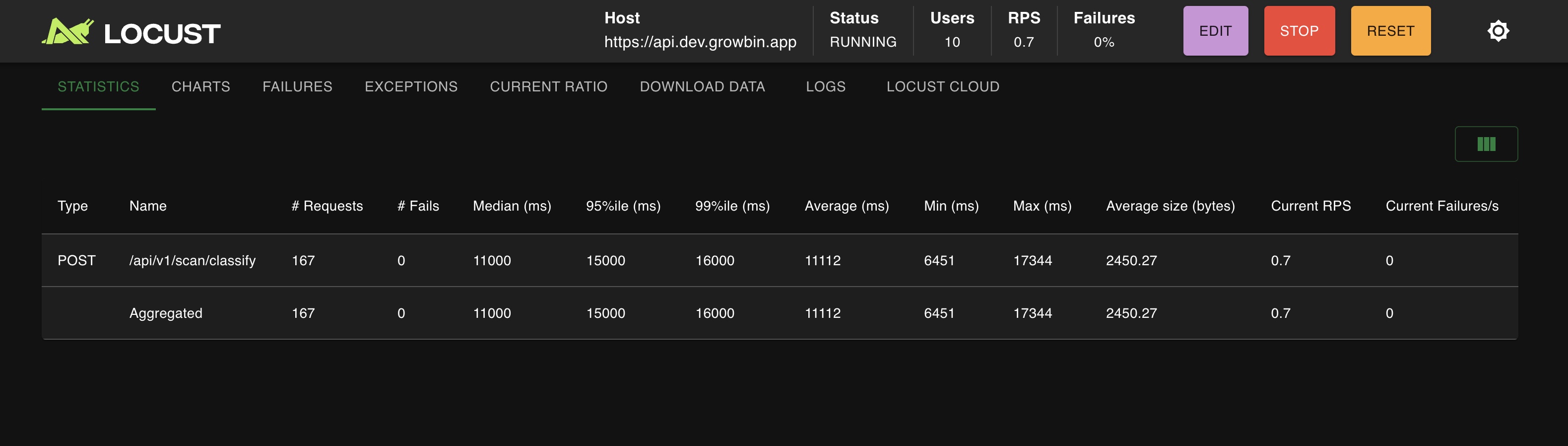
REST, non Istio: p99 16s, avg 11s 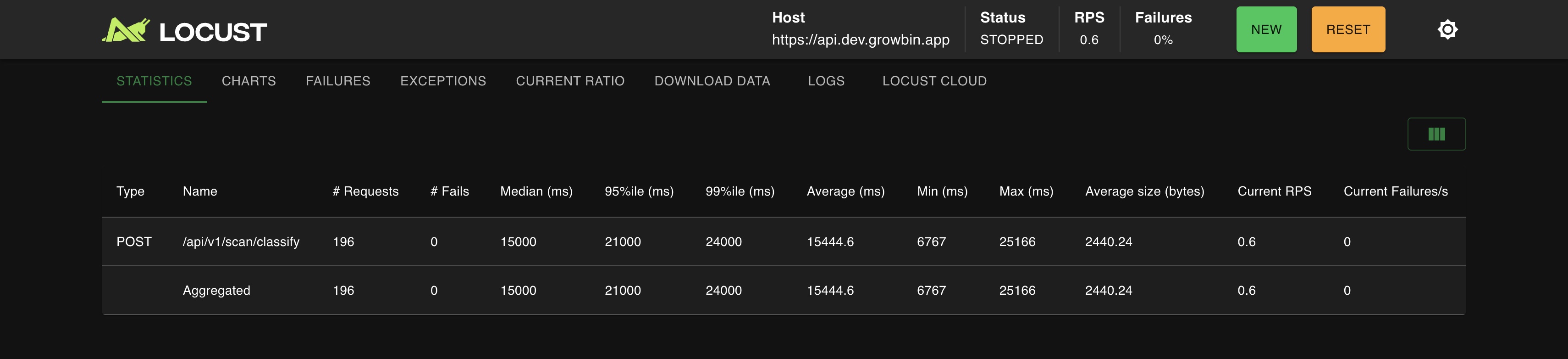
gRPC, Istio Sidecar: p99 24s, avg 15s CPU 사용량 (user 10, ramp-up 1)

REST + non Envoy Proxy: 0.04% 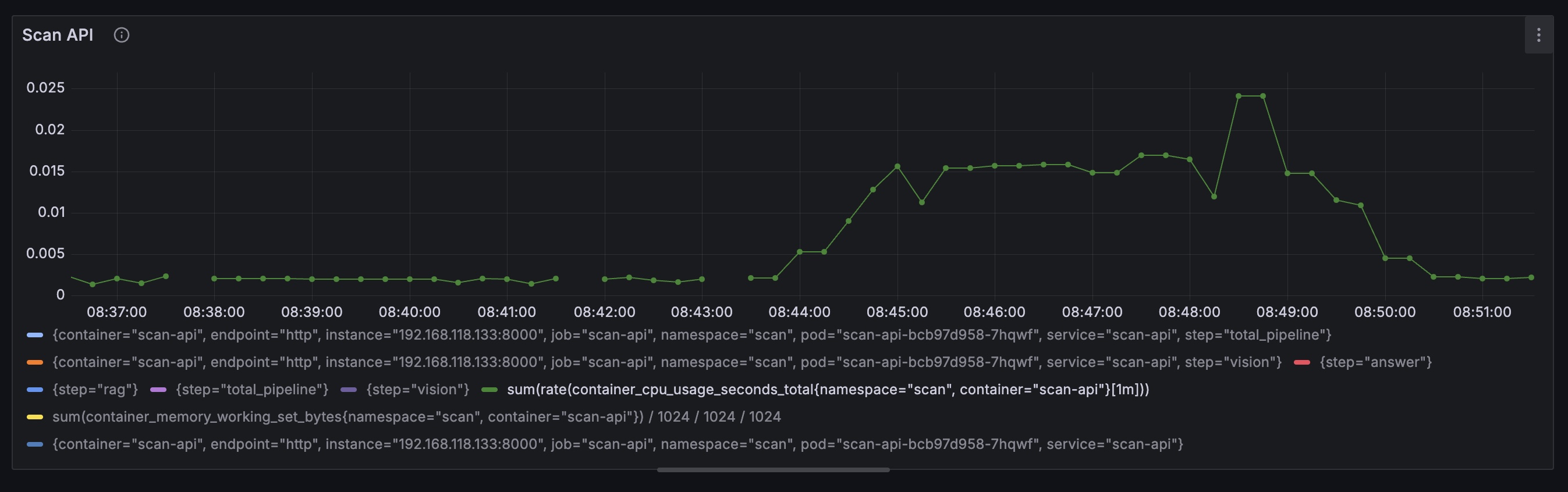
gRPC + Envoy Proxy: 0.025% Memory 사용량 (User 10, ramp-up 1)

REST + Envoy Proxy: 0.08 - 0.14GB 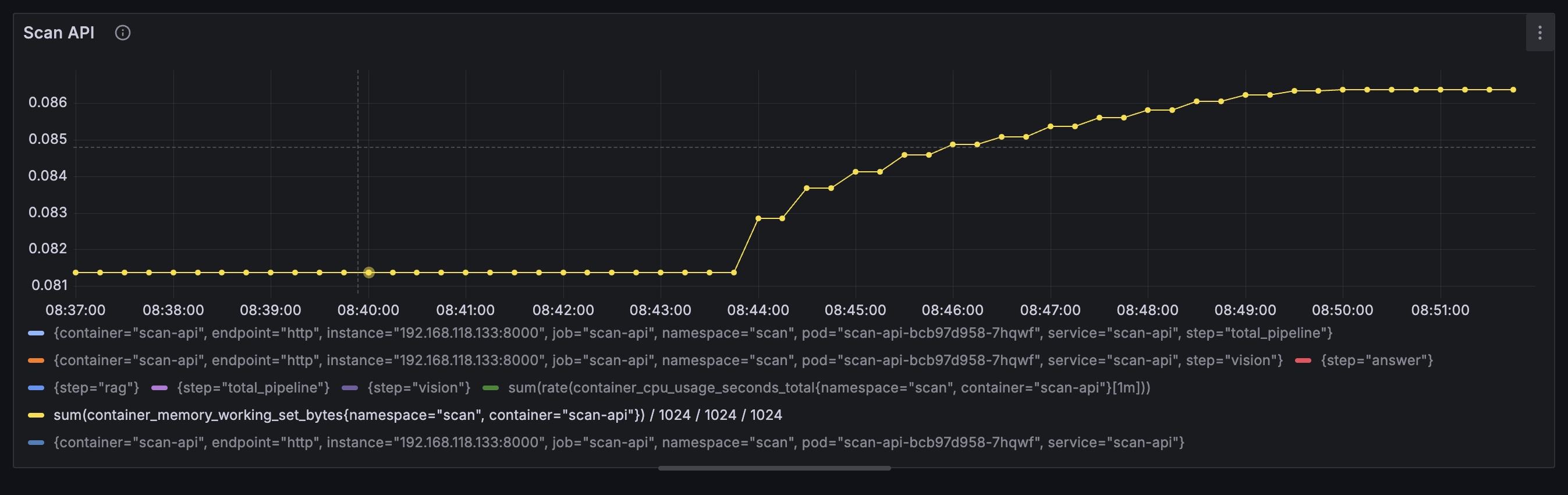
gRPC + Envoy Proxy: 0.086GB 실제 운영 환경에 gRPC를 적용하고 부하 테스트를 수행한 결과는 다음과 같다.
- Latency
- 네트워크 토폴로지 홉 증가와 Envoy Sidecar mTLS 복호화 과정이 더해지며 Latency가 소폭 증가했다.
- 리소스 효율
- 가장 큰 개선을 보인 곳은 CPU 사용량이다. Envoy Proxy로 Authz, Metric, 로깅 이원화와 gRPC로 프로토콜 경량화가 더해지며 CPU 사용량이 기존 대비 40% 감소했다.
- spike: 0.04% -> 0.025%, avg: 0.02% -> 0.015%
확장 가능한 구조를 향해
gRPC 도입은 단순한 개선을 넘어, 시스템의 확장성(Scalability)과 표준화(Standardization)를 위한 기반 작업이다.
- 엄격한 IDL(Proto) 도입으로 서비스 간 결합도를 낮추고 인터페이스 계약을 강화했다.
- ext_authz 등 gRPC 기반의 인프라 컴포넌트와의 통합이 용이해졌다.
- REST와 gRPC의 역할 분리를 통해, 이벤트 기반 아키텍처(EDA)로의 전환에 필요한 구조적 유연성을 확보했다.
Reference
- gRPC Official Documentation - Core Concepts
- Kubernetes - Service Load Balancing
- Istio - Traffic Management
Service
frontend.dev.growbin.app](https://frontend.dev.growbin.app)
'이코에코(Eco²) > Kubernetes Cluster+GitOps+Service Mesh' 카테고리의 다른 글
이코에코(Eco²) Service Mesh #1: Istio Sidecar 마이그레이션 (0) 2025.12.08 이코에코(Eco²) GitOps #06 - Namespace · RBAC · NetworkPolicy를 한 뿌리에서 (3) 2025.11.25 이코에코(Eco²) GitOps #05 Sync Wave (0) 2025.11.25 이코에코(Eco²) GitOps #04: Operator(Controller) 기반 클러스터 인프라 구성 자동화 (0) 2025.11.24 이코에코(Eco²) GitOps #03 네트워크 트러블슈팅 (0) 2025.11.24 - Strict Typing & Schema Definition: