-
skillsmp: senior-data-scientist이코에코(Eco²)/Skills 2026. 1. 30. 20:43
https://skillsmp.com/ko/skills/davila7-claude-code-templates-cli-tool-components-skills-development-senior-data-scientist-skill-md Date: 2026-01-30
Author: Claude Code, mangowhoiscloud
Source: https://skillsmp.com/ko
개요
Claude Code는 Skills라는 확장 기능을 통해 특정 도메인에 대한 전문성을 강화할 수 있습니다.
사용자가 생소한 도메인에 뛰어들 때 skill을 주입받은 에이전트와의 협업으로 온보딩(사전 학습 및 적용)을 가속합니다.
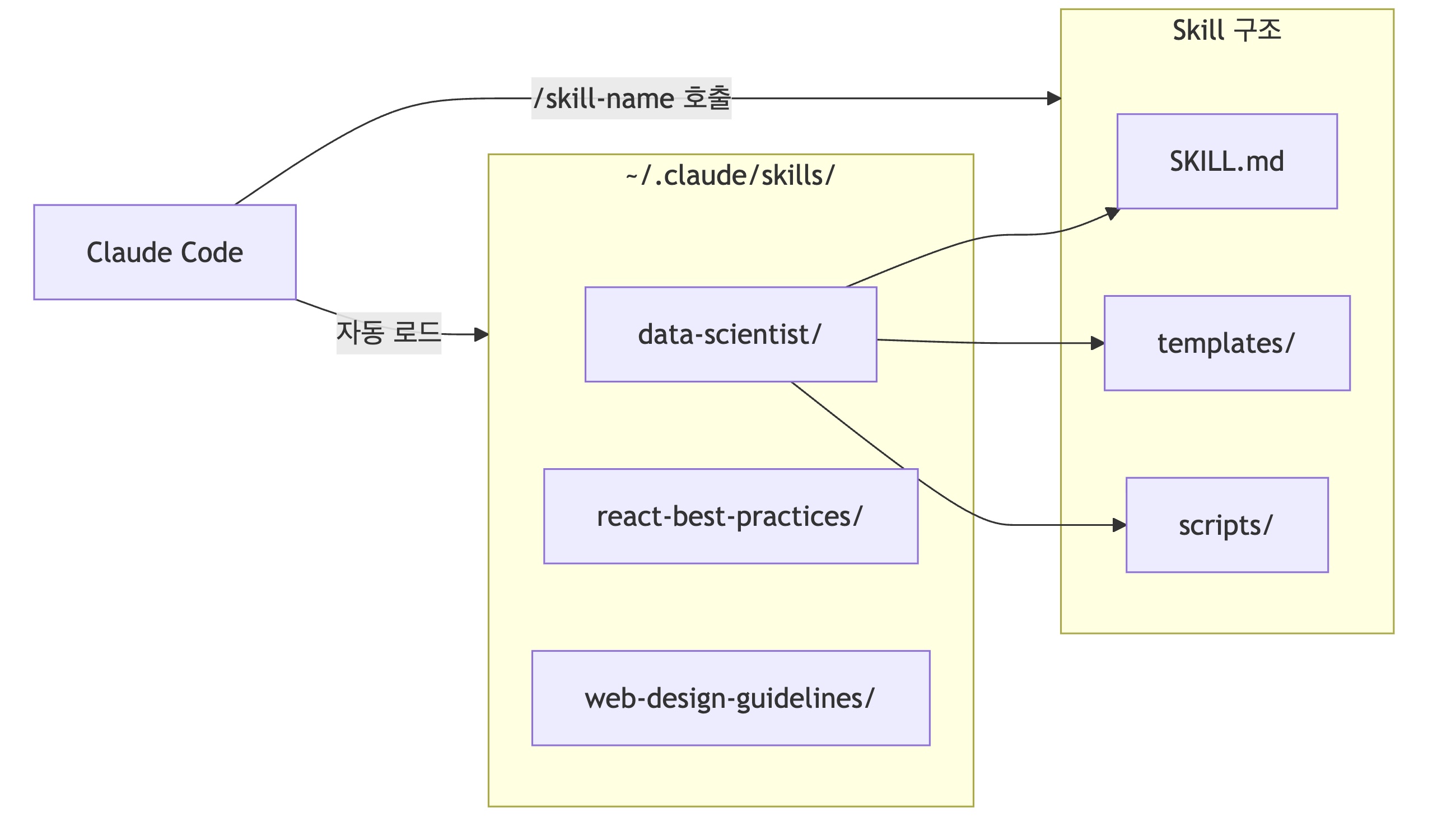
이 글에서는 skillsmp stars로 검증된 Data Scientist Skill을 설치하고 구성을 간략히 알아보도록 하겠습니다.Skills 아키텍처
Data Scientist Skill 설치
설치 위치
~/.claude/skills/ # 개인 Skills (모든 프로젝트에서 사용) .claude/skills/ # 프로젝트 Skills (해당 프로젝트에서만 사용)설치 방법
방법 1: 수동 설치
# 디렉토리 생성 mkdir -p ~/.claude/skills/data-scientist # SKILL.md 다운로드 curl -o ~/.claude/skills/data-scientist/SKILL.md \ https://raw.githubusercontent.com/VoltAgent/awesome-claude-code-subagents/main/categories/05-data-ai/data-scientist.md방법 2: Claude Code에서 직접 설치 요청
"{skillsmp link}을 설치해줘"설치 확인
ls ~/.claude/skills/ # data-scientist/ react-best-practices/ web-design-guidelines/
Data Scientist Skill 구조
메타데이터
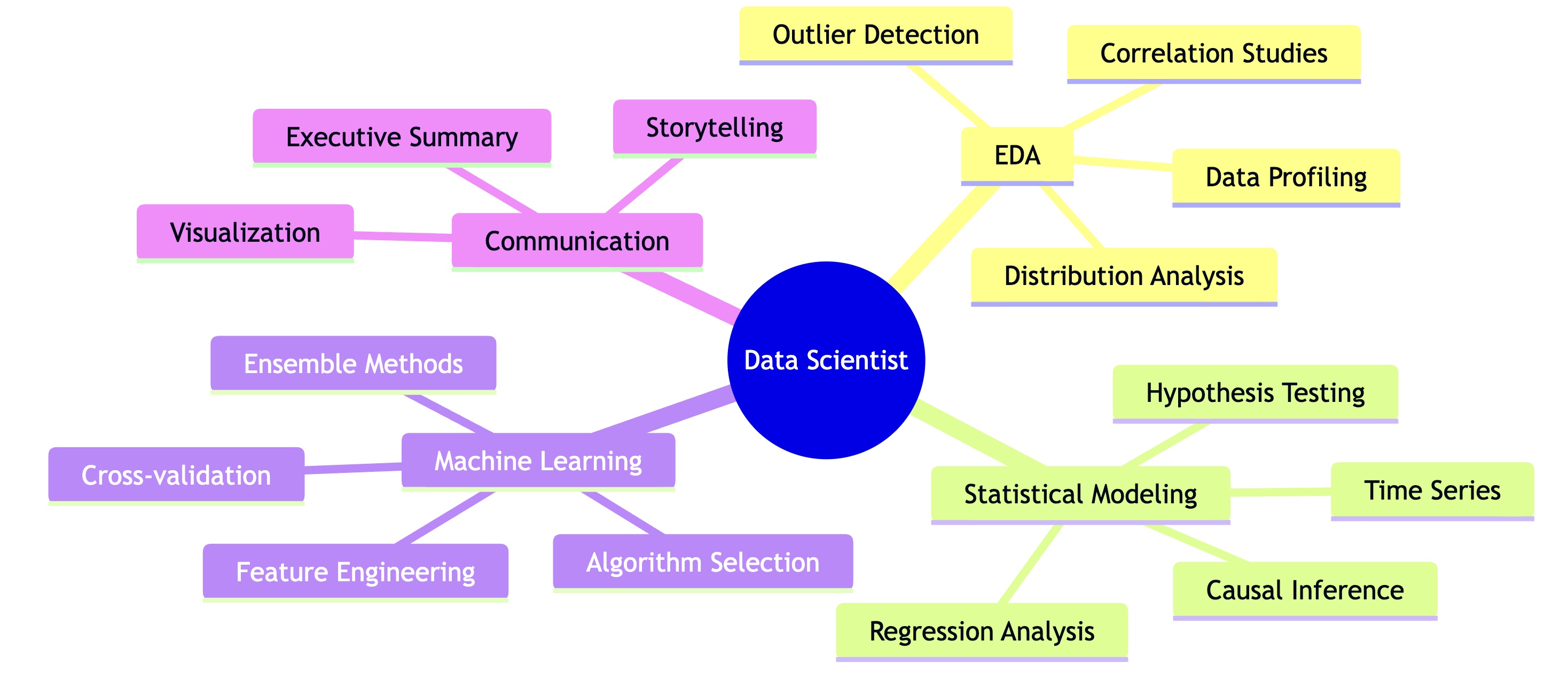
--- name: data-scientist description: Expert data scientist specializing in statistical analysis, machine learning, and business insights. tools: Read, Write, Edit, Bash, Glob, Grep ---Skills 구성 역량
워크플로우 (3단계)
단계 활동 체크리스트 1. Problem Definition 비즈니스 이해 → 성공 지표 정의 → 데이터 인벤토리 가설 수립, 방법론 선택 2. Implementation EDA → Feature Engineering → 모델 구축 → 검증 p<0.05, Cross-validation 3. Excellence 인사이트 도출 → 커뮤니케이션 → 모니터링 재현성, 비즈니스 가치
활용 예시
호출 방법
방법 1: 슬래시 커맨드
/data-scientist방법 2: 자연어
"데이터 사이언티스트 관점에서 이 문제를 분석해줘" "통계적 유의성을 검증해줘" "Feature importance를 분석해줘"실제 활용 시나리오
시나리오: 모델 선택
> 요청: "LightGBM vs XGBoost 중 어떤 걸 써야 할까?" < 응답: | 기준 | LightGBM | XGBoost | |------|----------|---------| | 속도 | 빠름 (leaf-wise) | 느림 (level-wise) | | 메모리 | 효율적 | 더 많이 사용 | | 대규모 데이터 | 적합 | 소/중규모 적합 | | 해석 가능성 | 복잡한 트리 | 균형 잡힌 트리 | 추천: 게임 데이터셋(대규모) → LightGBM
체크리스트
Data Scientist Skill이 따르는 품질 기준:
- Statistical significance p<0.05 verified
- Model performance validated thoroughly
- Cross-validation completed properly
- Assumptions verified rigorously
- Bias checked systematically
- Results reproducible consistently
- Insights actionable clearly
- Communication effective comprehensively
[추가 섹션 1] Skills의 작동 원리: 메타-도구 아키텍처
Skills는 코드가 아니다
Skills는 실행 가능한 코드가 아닌 프롬프트 기반 대화 맥락 수정자입니다.
측면 전통적 도구 Skills 목적 직접 작업 수행 복잡한 워크플로우 가이드 작동 방식 함수 실행 → 결과 반환 지시사항 주입 → Claude 변환 반환값 즉각적 결과 대화 맥락 + 실행 컨텍스트 수정 선택 방식 함수 호출 LLM 추론 (정규식/키워드 매칭 없음) 메타-도구 아키텍처
Skills 시스템은
Skill이라는 메타-도구를 통해 작동합니다:- Skill 도구: Tools 배열에 포함된 단일 도구, 모든 개별 Skills의 "관리자" 역할
- 개별 Skill: pdf, commit, data-scientist 등 특화된 명령 템플릿
- 선택 메커니즘: 알고리즘이 아닌 LLM 추론으로 결정
[추가 섹션 2] 실행 사이클 상세
Phase 1: 사용자 요청 & Skill 선택
사용자: "{도메인} 데이터 분석해줘" │ ▼ Claude: available_skills 섹션 스캔 │ ▼ Claude: "data-scientist" Skill 매칭 │ ▼ Claude: tool_use(Skill, command="data-scientist")Phase 2: 이중 메시지 주입
Skills의 핵심 메커니즘은 두 개의 사용자 메시지 주입입니다:
메시지 1 (isMeta: false) - UI에 표시됨
<command-message>The "data-scientist" skill is loading</command-message>메시지 2 (isMeta: true) - UI에 숨겨지고 API로만 전송
You are a senior data scientist with expertise in... [287줄의 상세 지시사항]왜 두 개인가?
- 투명성: 사용자는 어떤 Skill이 로드되었는지 알 수 있음
- 명확성: Claude는 상세한 지시사항을 받음
- 깔끔함: UI는 장황한 프롬프트로 오염되지 않음
Phase 3: API 요청 구성
메시지 배열: ┌─────────────────────────────────────────────────┐ │ User: "{도메인} 데이터 분석해줘" │ │ Assistant: tool_use(Skill, command="data-...") │ │ User: <command-message>Loading...</command-...> │ ← UI 표시 │ User: [287줄의 상세 Skill 프롬프트] │ ← UI 숨김 │ User: [권한 메시지] │ └─────────────────────────────────────────────────┘Phase 4: Claude의 Skill 맥락 처리
- Senior Data Scientist로 역할 전환
- 11개 영역 × 8개 역량 체크리스트 활성화
- 3단계 워크플로우 실행
- 결과 + Progress JSON 출력
[추가 섹션 3] 점진적 공개 (Progressive Disclosure)
Skills의 가장 중요한 설계 원칙은 점진적 공개입니다.
3단계 로딩 전략
Tier 로드 내용 목적 Tier 1 프론트매터만 (name, description) Skill 선택 판단 Tier 2 SKILL.md 전체 (287줄) 상세 지시사항 Tier 3 헬퍼 에셋 (scripts/, references/) 필요시만 로드 왜 점진적 공개가 중요한가?
❌ 모든 Skills를 한 번에 로드하면: [pdf 전체] + [commit 전체] + [data-scientist 전체] + ... = 컨텍스트 윈도우 포화 → 성능 저하 ✅ 점진적 공개: [pdf: 2줄] + [commit: 2줄] + [data-scientist: 2줄] + ... → 선택된 Skill만 전체 로드 = 컨텍스트 윈도우 효율적 사용
[추가 섹션 4] SKILL.md 각 섹션이 Claude 행동에 미치는 영향
4.1 Role Definition
You are a senior data scientist with expertise in statistical analysis, machine learning, and translating complex data into business insights.- 응답 톤, 전문성 수준, 관점을 조정
- 도메인 특화 지식 활성화
4.2 When Invoked (호출 시 행동)
When invoked: 1. Query context manager for business problems and data availability 2. Review existing analyses, models, and business metrics 3. Analyze data patterns, statistical significance, and opportunities 4. Deliver insights and models that drive business decisionsSkill 없이 vs Skill 활성화:
❌ Skill 없이: "네, 데이터를 분석해드리겠습니다. 어떤 파일인가요?" ✅ data-scientist Skill 활성화: "분석을 시작하기 전에 몇 가지 컨텍스트를 확인하겠습니다: 1. 이 분석의 비즈니스 목적은 무엇인가요? 2. 성공을 측정할 지표는 무엇인가요? 3. 데이터 파일의 위치를 알려주세요."4.3 Capability Lists (88개 체크포인트)
senior-data-scientist skills의 11개 영역 × 8개 항목 = 88개 역량 포인트는 Claude가 분석 시 암묵적 체크리스트로 작동합니다.
EDA 수행 시 Claude의 내부 프로세스: □ Data profiling 했나? → df.info(), df.describe() □ Distribution analysis 했나? → 히스토그램, KDE □ Correlation studies 했나? → 상관관계 매트릭스 □ Outlier detection 했나? → IQR, Z-score □ Missing data patterns 했나? → 결측치 히트맵 □ Feature relationships 했나? → Pairplot □ Hypothesis generation 했나? → 가설 명시 □ Visual exploration 했나? → 탐색적 시각화4.4 Communication Protocol
{ "requesting_agent": "data-scientist", "request_type": "get_analysis_context", "payload": { "query": "Analysis context needed: business problem, success metrics, data availability, stakeholder expectations, timeline, and decision framework." } }이 JSON이 정의하는 것:
- Claude가 무엇을 물어봐야 하는지 명시
- Multi-agent 환경에서 표준화된 통신 프로토콜
- 분석 시작 전 필수 수집 정보 체크리스트
4.5 Progress Tracking JSON
{ "agent": "data-scientist", "status": "analyzing", "progress": { "models_tested": 12, "best_accuracy": "87.3%", "feature_importance": "calculated", "business_impact": "$2.3M projected" } }이 JSON이 유도하는 행동:
- Claude가 정량적 진행 상황을 추적
- 결과를 구조화된 형식으로 보고
- 비즈니스 임팩트를 항상 포함
[추가 섹션 5] 설계 패턴 분석
ExpertPrompting 원칙
효과적인 페르소나 프롬프트는 3가지 특성을 가져야 합니다:
특성 Data Scientist Skill 적용 Distinguished (차별화) "Senior data scientist with expertise in..." 구체적 역할 Informative (정보성) 11개 영역, 88개 역량 목록 Automatic (자동화) Context Query JSON으로 자동 정보 수집 Two-Stage Role Immersion
Stage 1: Role-Setting Prompt "You are a senior data scientist..." Stage 2: Role-Feedback Prompt "When invoked: 1. Query context manager... 2. Review existing analyses... 3. Analyze data patterns... 4. Deliver insights..."이 2단계 접근법은 GPT-3.5에서 AQuA 데이터셋 정확도를 53.5% → 63.8%로 향상시킨 연구 결과를 반영합니다.
Behavioral Bundling
Skill은 행동의 묶음을 정의합니다:
data-scientist Skill의 Behavioral Bundle: 1. 항상 비즈니스 컨텍스트부터 확인 2. EDA를 체계적으로 수행 (8가지 관점) 3. 통계적 유의성 p<0.05 검증 4. Cross-validation 필수 수행 5. Feature importance 분석 포함 6. 비즈니스 임팩트 정량화 7. 재현 가능한 코드 제공 8. Progress JSON으로 보고
[추가 섹션 6] Skill 유형 분류
Type A: Script Automation Skills
- 예: pdf, image-processor
- 특징: Python/Bash 스크립트 오프로드
- 구조: SKILL.md + scripts/
Type B: Workflow Guidance Skills
- 예: data-scientist, code-reviewer
- 특징: 다단계 추론 워크플로우 가이드
- 구조: SKILL.md (순수 프롬프트)
Type C: Template-Based Skills
- 예: commit, pr-description
- 특징: 정형화된 출력 생성
- 구조: SKILL.md + templates/
data-scientist Skill = Type B (Workflow Guidance)
순수 프롬프트만으로 Claude의 행동을 변환하는 가장 정교한 유형입니다.
[추가 섹션 7] 실전 최적화 팁
Tip 1: 컨텍스트 프라이밍
❌ 나쁜 예: "데이터 분석해줘" ✅ 좋은 예: "{도메인} 데이터로 출시 첫 주 매출 예측 모델을 만들어줘. 타겟은 위시리스트 10,000개 이상 게임이고, 데이터는 data/steam_games.csv에 있어. 평가 지표는 RMSE와 R²로 해줘."→ Context Query 단계를 건너뛰고 바로 Implementation으로 진입
Tip 2: Progress Tracking 활용
요청: "현재 분석 진행 상황을 JSON으로 알려줘" 응답: { "agent": "data-scientist", "status": "implementing", "progress": { "eda_completed": true, "features_engineered": 15, "models_tested": 8, "best_model": "LightGBM", "best_rmse": "1234.5", "next_step": "Hyperparameter tuning" } }Tip 3: 체크리스트 검증 요청
요청: "Data science checklist 기준으로 이 분석을 검토해줘" 응답: ✅ Statistical significance p<0.05 verified ✅ Model performance validated (5-fold CV) ✅ Cross-validation completed (RMSE: 1234.5 ± 45.2) ⚠️ Assumptions partially verified (정규성 검정 필요) ✅ Bias checked (feature importance 분석 완료) ✅ Results reproducible (random_state=42 고정) ✅ Insights actionable (Top 5 features 식별) ✅ Communication effective (시각화 포함)
[추가 섹션 8] 요약
senior-data-scientist SKILL.md 287줄이 Claude에게 주입하는 것
# 주입 내용 효과 1 페르소나 Senior Data Scientist 역할 전환 2 행동 패턴 4단계 분석 워크플로우 3 체크리스트 88개 역량 포인트 4 통신 프로토콜 Context Query JSON 5 보고 형식 Progress Tracking JSON 6 품질 기준 p<0.05, Cross-validation, 재현성 7 협업 가이드 8개 다른 에이전트와의 연결점
References
Skills
Data Science
Skills 아키텍처
- Inside Claude Code Skills: Structure, prompts, invocation
- Claude Agent Skills: A First Principles Deep Dive
프롬프트 엔지니어링
'이코에코(Eco²) > Skills' 카테고리의 다른 글
Chat Eval Pipeline Integration Plan - Expert Review Loop Tracker (0) 2026.02.09 Claude Code Skills로 프론트엔드 AI 협업 체계 구축 (0) 2026.01.23 이코에코(Eco²) Agent Skills: Function Calling Agent (0) 2026.01.20 이코에코(Eco²) Agent Skills: Message Consumer Reference (0) 2026.01.19 이코에코(Eco²) Agent Skills: Checkpointer Reference (0) 2026.01.19