-
이코에코(Eco²) Message Queue #0: RabbitMQ + Celery 아키텍처 설계이코에코(Eco²)/Message Queue 2025. 12. 21. 22:25
개요
이코에코(Eco²) 백엔드는 현재 동기식 HTTP/gRPC 통신 기반으로 운영되고 있다. 7개 도메인 서비스(auth, character, chat, scan, my, location, image)가 Istio Service Mesh 위에서 동작하며, 분산 추적이 가능한 Observability 환경(EFK 로깅, Jaeger 트레이싱, Prometheus 메트릭)은 구축 완료된 상태다.
그러나 AI 파이프라인의 동기 대기 구간에서 심각한 레이턴시 누적이 발생하고 있으며, 이는 사용자 경험과 시스템 확장성 모두에 악영향을 미친다. 본 글에서는 RabbitMQ + Celery 기반의 비동기 아키텍처 전환 계획을 수립하고, 다른 메시지 브로커(NATS, Kafka)와의 비교 분석을 통해 기술 선정 근거를 제시한다.
목표
- AI 파이프라인(Scan, Chat)의 동기 대기 구간을 비동기로 전환
- API 응답 시간을 < 100ms로 개선 (현재 평균 10초, P99 12~25초)
- 시스템 장애 격리 및 자연스러운 백프레셔(Backpressure) 구현
현재 아키텍처의 한계
동기식 AI 파이프라인 구조
현재 Chat API와 Scan API는 GPT API 호출을 동기적으로 대기하는 구조다.
[현재 동기식 흐름 - 실측 데이터 기반] Client → API Server → GPT API → Response │ ├── Vision Model 호출 (~3.5초, 3~4.5초) ├── Rule-based Retrieval (~0.01초, Dictionary 매칭) ├── Answer Model 호출 (~7초, Vision의 약 2배) └── Character Reward Matching (~0.04초) 총 레이턴시: 평균 8~11초, P99 12~15초 (부하 시 최대 25초 Spike)참고: Scan API 성능 측정 및 시각화에서 Prometheus 기반 측정 결과, Answer 단계가 전체 응답 시간의 70~80%를 점유하며 병목을 주도함을 확인했다. 동일한 GPT-4o 모델을 사용함에도 Vision(이미지 분류)보다 Answer(JSON 답변 생성)에서 출력 토큰 양이 많아 latency가 2배 가량 길다.
# 현재 ChatService - 동기 대기 (asyncio.to_thread 사용) async def _run_image_pipeline(self, user_input: str, image_url: str): result = await asyncio.to_thread( self._image_pipeline, # GPT API 호출 포함 - 블로킹 user_input, image_url, save_result=False, verbose=False, ) return WasteClassificationResult(**result)문제점 분석
문제 영향 심각도 API 응답 지연 사용자가 평균 10초, 최대 25초 대기 P0 리소스 점유 API Pod가 GPT 응답 대기 중 유휴 상태 P1 장애 전파 GPT Rate Limit → API 전체 타임아웃 P0 확장성 제한 동시 요청 처리량 = API Pod 수 × 쓰레드 수 (기본 6) P1 재시도 불가 GPT 실패 시 사용자가 다시 요청해야 함 P2 실측 병목 분석 (출처: Scan API 성능 측정):
단계 평균 소요 시간 전체 비중 비고 Vision (이미지 분류) ~3.5초 ~30% GPT-4o Vision 호출 Rule-based Retrieval ~0.01초 <1% Dictionary 매칭 Answer (답변 생성) ~7초 ~70% 병목 구간 Character Matching ~0.04초 <1% gRPC 내부 호출 핵심 문제: GPT API 호출이라는 외부 I/O 작업을 API 서버의 요청 컨텍스트 안에서 동기적으로 처리하고 있다.
asyncio.to_thread로 서버 멈춤은 방지했으나, 개별 요청 처리 시간 자체를 줄이지는 못한다.
LLM API 응답 속도가 곧 Scan API의 Latency가 되는 구조다.
메시지 브로커 선정: RabbitMQ vs NATS vs Kafka
비교 분석
비동기 처리를 위한 메시지 브로커로 3가지 후보를 검토했다.
비교 항목 RabbitMQ NATS (JetStream) Kafka 주요 용도 Task Queue, RPC Pub/Sub, Request-Reply Event Streaming, CDC 메시지 패턴 Point-to-Point, Fan-out Pub/Sub, Queue Group Pub/Sub (Consumer Group) 메시지 보장 At-least-once (ACK) At-least-once (JetStream) At-least-once (Offset) 순서 보장 Queue 내 FIFO Subject 내 순서 Partition 내 순서 지연 시간 ~1ms ~0.5ms ~5ms 처리량 10K~50K msg/s 100K+ msg/s 1M+ msg/s 메시지 보관 TTL 기반 삭제 Stream 기반 보관 Log 기반 영구 보관 클러스터 구성 Quorum Queue (3노드 권장) NATS Cluster (3노드) KRaft (3노드 필수) 메모리 사용 중간 (500MB~2GB) 낮음 (100MB~500MB) 높음 (2GB~8GB) Python 생태계 ✅ Celery 네이티브 지원 ⚠️ nats-py (비교적 미성숙) ⚠️ faust, kafka-python 운영 복잡도 중간 낮음 높음 학습 곡선 중간 낮음 높음 용도별 적합성 분석
1. Kafka: Event Streaming & CDC에 최적화
[Kafka 강점] ✅ 대용량 이벤트 스트리밍 (수백만 msg/s) ✅ 이벤트 영구 보관 (Log Compaction) ✅ CDC (Debezium) 네이티브 통합 ✅ 다중 Consumer Group 재생(Replay) 지원 ✅ 스키마 레지스트리(Avro) 지원 [Kafka 약점] ❌ 리소스 오버헤드 (ZooKeeper/KRaft + Broker × 3) ❌ Task Queue 패턴에 부적합 (작업 단위 ACK 어려움) ❌ Python 생태계 취약 (Celery 미지원) ❌ 운영 복잡도 높음 (파티션 관리, 리밸런싱)결론: Kafka는 Phase 2(CDC/Event Sourcing)에 도입 예정. 현재 비즈니스 로직용 Task Queue로는 적합하지 않음.
2. NATS: 경량 Pub/Sub에 최적화
[NATS 강점] ✅ 초경량 (바이너리 ~10MB) ✅ 초저지연 (~0.5ms) ✅ 간단한 Pub/Sub 패턴 ✅ Kubernetes 네이티브 (Helm Chart) ✅ JetStream으로 내구성 보장 가능 [NATS 약점] ❌ Python 생태계 미성숙 (Celery 미지원) ❌ 복잡한 라우팅(Topic Exchange, Headers Exchange) 미지원 ❌ Dead Letter Queue 패턴 직접 구현 필요 ❌ Worker 프레임워크 부재 (직접 Consumer 구현 필요)결론: NATS는 Go/Rust 기반 마이크로서비스에 적합. Python 백엔드에서는 Worker 프레임워크 부재가 치명적.
3. RabbitMQ: Task Queue & Workflow에 최적화
[RabbitMQ 강점] ✅ Celery 네이티브 브로커 지원 ✅ 다양한 Exchange 타입 (Direct, Topic, Fanout, Headers) ✅ Dead Letter Exchange (DLX) 내장 ✅ Message TTL, Priority Queue 지원 ✅ Ack/Nack/Reject 세밀한 메시지 제어 ✅ Quorum Queue로 고가용성 보장 ✅ 성숙한 관리 UI (Management Plugin) [RabbitMQ 약점] ❌ 대용량 스트리밍에 부적합 (vs Kafka) ❌ Kafka 수준의 처리량 미달 ❌ 메시지 영구 보관 미지원 (소비 후 삭제)결론: 비즈니스 로직용 Task Queue로 최적. Celery와의 완벽한 통합이 결정적.
RabbitMQ + Celery 선정 근거
Martin Fowler와 Confluent에서 제시하는 메시지 브로커 선택 의사결정 프레임워크를 따랐다.
┌───────────────────────────────────────────────────────────────────────┐ │ 메시지 브로커 선택 의사결정 트리 │ ├───────────────────────────────────────────────────────────────────────┤ │ │ │ 1. 주요 용도가 무엇인가? │ │ │ │ │ ├─► 작업 큐 (Task Queue) ──────────────────► RabbitMQ │ │ │ • 비동기 작업 처리 │ │ │ • 작업 단위 ACK/재시도 │ │ │ • 워크플로우 체이닝 │ │ │ │ │ ├─► 이벤트 스트리밍 (Event Streaming) ────► Kafka │ │ │ • 이벤트 영구 보관 │ │ │ • 다중 Consumer 재생(Replay) │ │ │ • CDC, 데이터 파이프라인 │ │ │ │ │ └─► 실시간 Pub/Sub ───────────────────────► NATS / Redis Pub/Sub │ │ • 초저지연 (<1ms) │ │ • 단순 팬아웃 │ │ • 메시지 영속성 불필요 │ │ │ │ 2. 처리 보장이 필요한가? │ │ │ │ │ ├─► At-least-once + 작업 단위 ACK ────────► RabbitMQ │ │ ├─► At-least-once + 오프셋 기반 ──────────► Kafka │ │ └─► At-most-once (Fire-and-forget) ────────► NATS Core │ │ │ │ 3. Python 생태계 통합이 중요한가? │ │ │ │ │ ├─► Celery 사용 필요 ─────────────────────► RabbitMQ ✅ │ │ └─► 직접 Consumer 구현 가능 ──────────────► Kafka/NATS │ │ │ └───────────────────────────────────────────────────────────────────────┘Eco² 백엔드의 주요 요구사항:
- ✅ GPT API 호출 비동기 처리 (Task Queue)
- ✅ 작업 실패 시 재시도 + DLQ (At-least-once)
- ✅ Python/FastAPI 환경 (Celery 통합)
- ❌ 이벤트 영구 보관 (현재 불필요, Phase 2에서 Kafka 도입)
결론: 의사결정 트리에 따라 RabbitMQ + Celery가 최적 선택.
선정 이유 요약
요구사항 RabbitMQ + Celery 비고 GPT API 비동기 호출 ✅ Task 단위 분리 핵심 요구사항 재시도 정책 ✅ Celery autoretry_for,retry_backoffExponential Backoff 내장 실패 메시지 격리 ✅ Dead Letter Queue (DLX) 자동 라우팅 작업 체이닝 ✅ chain(),chord(),group()AI 파이프라인 워크플로우 결과 조회 ✅ AsyncResult + Redis Backend 클라이언트 폴링 지원 작업 취소 ✅ revoke()사용자 요청 취소 작업 우선순위 ✅ Priority Queue VIP 사용자 우선 처리 모니터링 ✅ Flower (Celery 대시보드) 실시간 작업 모니터링 Python 통합 ✅ 네이티브 지원 FastAPI, Django 즉시 연동 핵심 결정: Celery의 가치
NATS나 Kafka로도 비동기 처리는 가능하다. 그러나 Worker 프레임워크를 직접 구현해야 한다:
# NATS 사용 시: Consumer 직접 구현 필요 async def message_handler(msg): data = json.loads(msg.data.decode()) try: result = await process_gpt_call(data) # 비즈니스 로직 await msg.ack() except Exception as e: # 재시도 로직 직접 구현 retry_count = int(msg.headers.get('retry-count', 0)) if retry_count < 3: await nc.publish( msg.subject, msg.data, headers={'retry-count': str(retry_count + 1)} ) else: # DLQ 직접 라우팅 await nc.publish('dlq.' + msg.subject, msg.data) await msg.nak() # 모든 인프라 코드 직접 작성... # - 재시도 정책 # - DLQ 라우팅 # - 결과 저장 # - 작업 취소 # - 작업 체이닝 # - 모니터링# Celery 사용 시: 선언적 설정으로 동일 기능 @celery_app.task( bind=True, autoretry_for=(OpenAIError,), retry_backoff=True, retry_kwargs={'max_retries': 3}, acks_late=True, ) def process_gpt_call(self, data): return call_gpt_api(data) # 비즈니스 로직만 집중Celery가 제공하는 것들:
- 재시도 정책 (Exponential Backoff, Jitter)
- Dead Letter Queue 자동 라우팅
- 결과 저장 (Redis, DB, S3)
- 작업 체이닝 (Workflow)
- 작업 취소/폐기 (Revoke)
- 우선순위 큐
- 스케줄링 (Celery Beat)
- 모니터링 (Flower)
- Rate Limiting
- ETA/Countdown (지연 실행)
1인 운영 환경에서 이 모든 것을 직접 구현하는 것은 비현실적이다.
Opus 4.5가 있으니 커스텀 Worker 구현이 불가능한 일은 아니겠지만 토큰비를 아낀다고 생각하자.
목표 아키텍처
전체 흐름

시퀀스 다이어그램
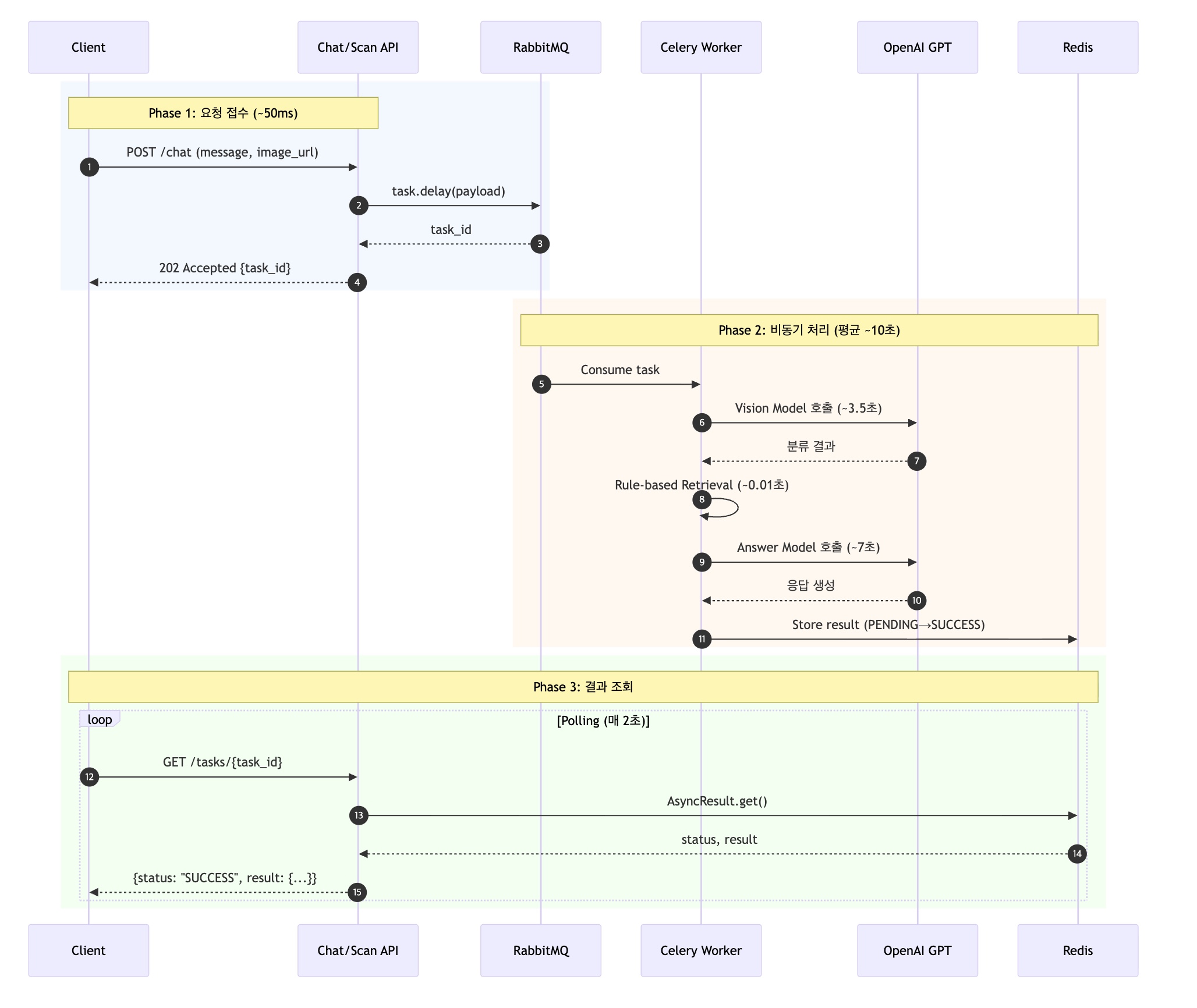
Exchange/Queue 설계
[Topic Exchange 구조] eco2.tasks (exchange) ├── chat.vision → Q: chat-vision-queue → Worker-AI ├── chat.answer → Q: chat-answer-queue → Worker-AI ├── scan.vision → Q: scan-vision-queue → Worker-AI ├── scan.answer → Q: scan-answer-queue → Worker-AI ├── scan.reward → Q: scan-reward-queue → Worker-Storage └── *.failed → Q: eco2-dlq → DLQ Handler [Queue 설정] - Type: Quorum Queue (고가용성) - TTL: 24시간 (만료 시 DLQ로 이동) - Max Retries: 3회 (Exponential Backoff: 10s → 60s → 300s)Celery Task 설계
# domains/_shared/celery/tasks/ai_tasks.py from celery import shared_task, chain from openai import OpenAIError @shared_task( bind=True, name='chat.vision', queue='chat-vision-queue', autoretry_for=(OpenAIError, TimeoutError), retry_backoff=True, retry_backoff_max=300, retry_kwargs={'max_retries': 3}, acks_late=True, # 작업 완료 후 ACK (안정성) reject_on_worker_lost=True, # Worker 손실 시 재큐 ) def classify_image(self, image_url: str, user_input: str) -> dict: """Vision Model을 통한 이미지 분류""" return call_vision_model(image_url, user_input) @shared_task( bind=True, name='chat.answer', queue='chat-answer-queue', autoretry_for=(OpenAIError, TimeoutError), retry_backoff=True, retry_kwargs={'max_retries': 3}, ) def generate_answer(self, classification_result: dict) -> dict: """Answer Model을 통한 응답 생성""" disposal_rules = get_disposal_rules(classification_result) return call_answer_model(classification_result, disposal_rules) # 파이프라인 체이닝 def process_chat_image(image_url: str, user_input: str) -> AsyncResult: """이미지 채팅 파이프라인 실행""" workflow = chain( classify_image.s(image_url, user_input), generate_answer.s(), ) return workflow.apply_async()Celery 프로덕션 베스트 프랙티스
# domains/_shared/celery/config.py from celery import Celery app = Celery('eco2') app.conf.update( # ===== 브로커 설정 ===== broker_url='amqp://user:pass@rabbitmq:5672/eco2', broker_connection_retry_on_startup=True, broker_transport_options={ 'confirm_publish': True, # 발행 확인 (메시지 유실 방지) }, # ===== 결과 백엔드 ===== result_backend='redis://redis:6379/0', result_expires=86400, # 24시간 (GPT 비용 고려) # ===== Worker 설정 ===== worker_prefetch_multiplier=1, # 공정한 작업 분배 (긴 작업에 필수) worker_concurrency=4, # GPT API 동시 호출 수 제한 # ===== 안정성 설정 ===== task_acks_late=True, # 작업 완료 후 ACK (Worker 손실 대비) task_reject_on_worker_lost=True, task_track_started=True, # STARTED 상태 추적 # ===== 재시도 설정 ===== task_default_retry_delay=10, # 기본 재시도 대기 (초) task_max_retries=3, # ===== 큐 설정 (Quorum Queue) ===== task_default_queue='eco2.default', task_default_queue_type='quorum', # Celery 5.5+ (고가용성) # ===== 직렬화 ===== task_serializer='json', result_serializer='json', accept_content=['json'], # ===== 타임존 ===== timezone='Asia/Seoul', enable_utc=True, )핵심 설정 설명:
설정 값 이유 worker_prefetch_multiplier1 GPT 호출은 10~30초 소요. 기본값(4)이면 한 Worker가 작업을 독점 task_acks_lateTrue 작업 완료 전 Worker 다운 시 재큐. 메시지 유실 방지 confirm_publishTrue Broker가 메시지 수신 확인. 네트워크 장애 대응 task_default_queue_typequorum Classic Queue 대비 데이터 안정성 향상 (Raft 기반) API 엔드포인트 변경
# domains/chat/api/routes.py from fastapi import APIRouter, BackgroundTasks, status from celery.result import AsyncResult router = APIRouter() @router.post( "/chat", status_code=status.HTTP_202_ACCEPTED, response_model=TaskAcceptedResponse, ) async def send_message(payload: ChatMessageRequest): """ 채팅 메시지 전송 (비동기) - 즉시 task_id 반환 (~50ms) - 실제 처리는 백그라운드 Worker에서 수행 """ if payload.image_url: result = process_chat_image.delay( str(payload.image_url), payload.message, ) else: result = process_chat_text.delay(payload.message) return TaskAcceptedResponse( task_id=result.id, status="PENDING", poll_url=f"/tasks/{result.id}", ) @router.get("/tasks/{task_id}", response_model=TaskStatusResponse) async def get_task_status(task_id: str): """작업 상태 조회""" result = AsyncResult(task_id) response = TaskStatusResponse( task_id=task_id, status=result.status, ) if result.ready(): if result.successful(): response.result = result.result else: response.error = str(result.result) return response
인프라 구성
노드 배치
[현재 노드 구성] k8s-rabbitmq (t3.small, 2GB) → RabbitMQ 전용 노드 (이미 존재) k8s-api-* → API 서비스 노드 [추가 구성] Celery Worker → API 노드에 Sidecar 또는 별도 Pod로 배포Kubernetes 리소스
# workloads/domains/celery/base/deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: celery-worker-ai spec: replicas: 2 template: spec: containers: - name: celery-worker image: mng990/eco2:celery-worker-latest command: ["celery", "-A", "tasks", "worker"] args: - "--loglevel=INFO" - "--concurrency=4" - "--queues=chat-vision-queue,chat-answer-queue,scan-vision-queue,scan-answer-queue" env: - name: CELERY_BROKER_URL valueFrom: secretKeyRef: name: rabbitmq-secret key: url - name: CELERY_RESULT_BACKEND value: "redis://dev-redis:6379/1" resources: requests: memory: "512Mi" cpu: "250m" limits: memory: "1Gi" cpu: "1000m"RabbitMQ 설정 (Quorum Queue)
# workloads/messaging/rabbitmq/base/rabbitmq.yaml apiVersion: rabbitmq.com/v1beta1 kind: RabbitmqCluster metadata: name: eco2-rabbitmq spec: replicas: 1 # 단일 노드 (dev), prod는 3 persistence: storage: 10Gi rabbitmq: additionalConfig: | default_vhost = eco2 default_user = eco2 default_permissions.configure = .* default_permissions.read = .* default_permissions.write = .* # Quorum Queue 기본값 cluster_formation.target_cluster_size_hint = 1 queue_leader_locator = balanced
구현 로드맵
Phase 0: Observability (완료) ├── EFK 로깅 파이프라인 구축 ✅ ├── Jaeger 분산 트레이싱 구축 ✅ └── Log-Trace Correlation 구현 ✅ Phase 1: MQ 인프라 구축 ├── RabbitMQ, Topology Operator 배포 ├── Exchange/Queue 구성 ├── Celery 공통 모듈 개발 └── Result Backend (Redis) 설정 Phase 2: Chat API 비동기 전환 ├── Chat 파이프라인 Task 분리 ├── API 엔드포인트 변경 (202 Accepted) ├── 클라이언트 폴링 구현 └── E2E 테스트 Phase 3: Scan API 비동기 전환 ├── Scan 파이프라인 Task 분리 ├── 보상 로직 Worker-Storage로 분리 └── 통합 테스트 Phase 4: 안정화 & 모니터링 ├── Flower 대시보드 배포 ├── DLQ 모니터링 알림 설정 └── 부하 테스트 & 튜닝
예상 효과
정량적 개선
지표 AS-IS (동기) TO-BE (비동기) 개선율 API 응답 시간 평균 10초, P99 12~25초 < 100ms (응답 한정, 답변 생성은 push 알림으로 제공) 99%+ 동시 처리량 ~6 req (스레드 풀 제한) Worker 수평 확장 10x+ GPT 장애 시 영향 504 Gateway Timeout (60초) 격리 (DLQ) - 재시도 사용자 수동 자동 (3회 + Backoff) - 실측 근거: 동시 접속 10명까지는 안정적 처리, 100명 시 504 Timeout 다발 (성능 측정 결과)
정성적 개선
- 사용자 경험: 즉각적인 응답 + 진행 상태 표시
- 시스템 안정성: GPT API 장애가 API 서버에 전파되지 않음
- 확장성: Worker 수평 확장으로 처리량 선형 증가
- 운영 효율: Flower 대시보드로 실시간 모니터링
비용 분석
[AS-IS] - API Pod: t3.medium (vCPU 2) - 스레드 풀: 기본 6개 (2 + 4) - CPU 사용률: ~2%, Memory: ~7% (실측) - 병목: GPT 대기 중 스레드 점유 → 동시 처리 ~6명 제한 [TO-BE] - API Pod: 경량화 (응답만 처리, 즉시 반환) - Worker Pod: 2개 (GPT 호출 전담, 수평 확장 가능) - RabbitMQ: 1개 (t3.small, 기존 노드 활용) 예상 비용 변화: 유사 또는 소폭 감소 (API Pod 리소스 절감 vs Worker Pod 추가)
향후 확장 계획
Phase 2: Command-Event Separation (Kafka + RabbitMQ 병행)
RabbitMQ는 Task Queue(Command)로, Kafka는 Event Bus(Event)로 역할을 분리한다.
┌─────────────────────────────────────────────────────────────────┐ │ Command-Event Separation Architecture │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ RabbitMQ (Command) Kafka (Event) │ │ ───────────────── ───────────── │ │ │ │ "무엇을 해야 하는가" "무슨 일이 일어났는가" │ │ │ │ • ProcessImage Task • ScanCompleted Event │ │ • SendEmail Task • CharacterGranted Event │ │ • GenerateReport Task • UserRegistered Event │ │ │ │ 특성: 특성: │ │ • 명령형 (Imperative) • 과거형 (Past tense) │ │ • 하나의 Worker만 처리 • 여러 Consumer가 구독 │ │ • 처리 후 삭제 • 영구 보존 (Replay) │ │ • Retry/DLQ 내장 • Offset 기반 재처리 │ │ │ └─────────────────────────────────────────────────────────────────┘ [이론적 기반 - Foundations] ├── 01. The Log (Jay Kreps) → Kafka 설계 철학 ├── 02. Event Sourcing (Fowler) → 상태 대신 이벤트 저장 ├── 08. Transactional Outbox → At-Least-Once 보장 └── 09. Debezium CDC → WAL Capture구현 흐름 (Phase 2)
Celery Task 완료 │ ▼ Event Store + Outbox 저장 (같은 트랜잭션) │ │ PostgreSQL WAL ▼ Debezium CDC ──▶ Kafka ──┬──▶ Character Consumer (보상 지급) ├──▶ My Consumer (Projection) └──▶ Analytics Consumer (분석)WebSocket 실시간 알림 (선택적)
[고려 중] Option1: 클라이언트 폴링 (2초 간격) Option2: WebSocket + Redis Pub/Sub로 실시간 푸시
References
사례 및 베스트 프랙티스
- 올리브영 테크 블로그 - RabbitMQ 도입기
- Amazon MQ - RabbitMQ & Celery Best Practices
- Netflix Tech Blog - Microservices
- Uber Engineering - DOMA
- Confluent - Kafka vs RabbitMQ
- Martin Fowler - Event-Driven Architecture
GitHub
Service
'이코에코(Eco²) > Message Queue' 카테고리의 다른 글
이코에코(Eco²) Message Queue #5: Celery Chain + Celery Events (1) (0) 2025.12.23 이코에코(Eco²) Message Queue #4: SSE vs Webhook vs Websocket (0) 2025.12.22 이코에코(Eco²) Message Queue #3: Scan 비동기 파이프라인 로드맵 (0) 2025.12.22 이코에코(Eco²) Message Queue #2: RabbitMQ 구축 (0) 2025.12.22 이코에코(Eco²) Message Queue #1: MQ 적용 가능 영역 도출 (1) 2025.12.21